我们经常被问到的一个问题是:在 COMSOL Multiphysics® 软件中能求解多大的模型?这个问题看似简单,但要给出全面且准确的回答,却需要深入探讨多个关键因素,包括数值方法、建模策略与求解算法、计算机硬件性能,以及如何最好的处理计算要求高的问题。这篇文章,让我们更深入地探讨这个话题。
编者注:这篇文章最初于发布 2014 年 10 月 24 日。现在已经更新以反映新版本软件的特点和功能。
先来看一些数据
我们先建立一个温度在域内稳态分布的三维模型,然后研究随自由度数增加的内存需求和求解时间。该模型是在一台典型的台式电脑(Intel® Xeon® W-2145 CPU,32GB 内存,固态硬盘)上,使用默认的求解器在逐渐细化的网格上求解。
首先,我们将从两个报告量来查看当模型大小增加时的内存需求:虚拟内存和物理内存。虚拟内存是软件向操作系统请求的内存量。(这些数据来自 Windows® 系统,所有支持的操作系统的内存管理都非常相似)。物理内存是指被占用的 RAM 内存的数量。物理内存总是小于虚拟内存和安装的 RAM 数量,因为操作系统以及在计算机上运行的其他程序也需要占用一些 RAM 内存。在占用内存的某个最高点,物理 RAM 的可用空间已经用完,相当一部分数据会驻留在固态硬盘上。还有另一个点,当超过这个点时,软件将报告没有足够的内存,所以模型根本无法求解。显然,为计算机增加更多的内存能求解更大的模型,我们可以通过线性外推来预测内存需求。
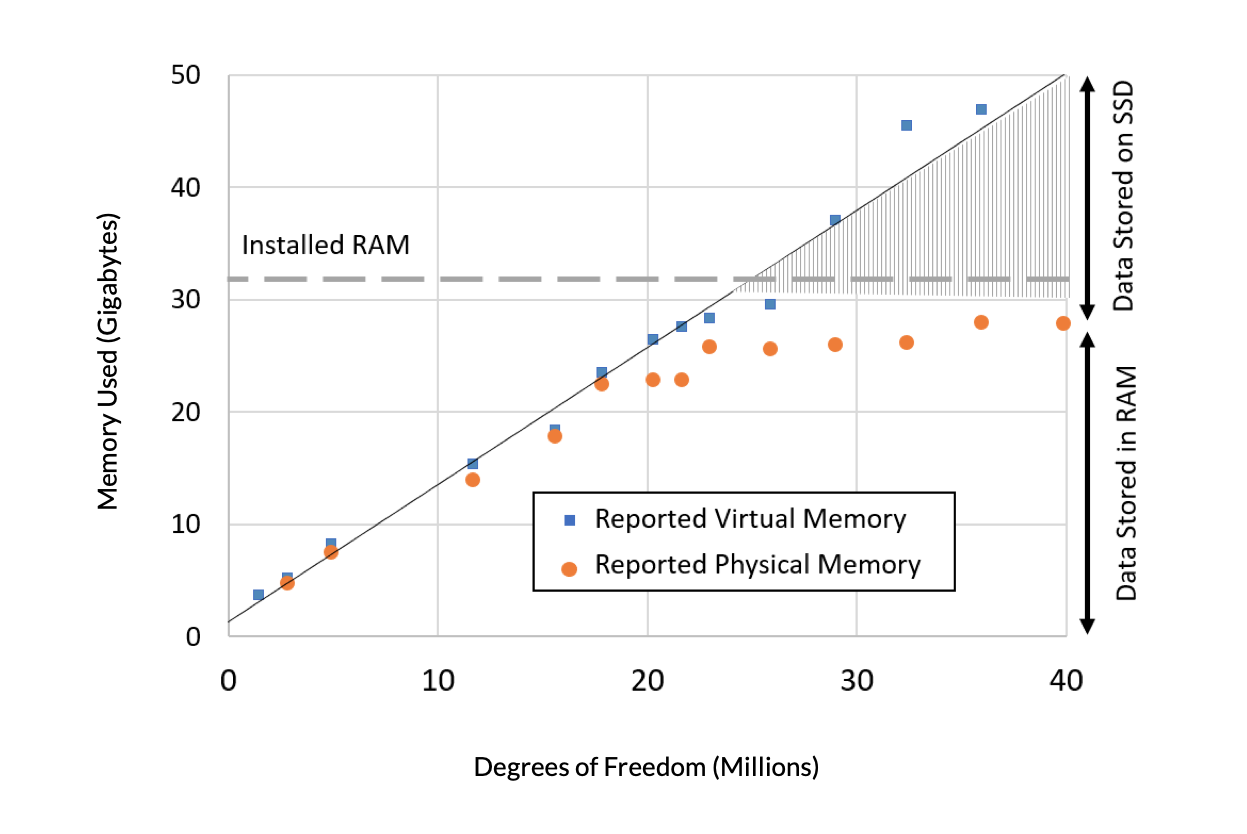
图1. 使用一台 32 GB 内存的计算机模拟的包含固体传热的模型。所需的虚拟内存(蓝色)和物理内存(橙色)与问题大小的对比,以百万个自由度表示。
接下来,让我们来看看这个问题的求解时间与自由度的关系。求解时间显示两个不同的区域。一个二阶多项式适合所需虚拟内存量小于安装的 RAM 区域,这个曲线几乎是线性的。另一个二阶多项式适合剩余的数据,即虚拟内存高于安装的 RAM。这条曲线的斜率更加陡,因为在这个系统中,访问存储在虚拟内存中的模型数据需要更长的时间。
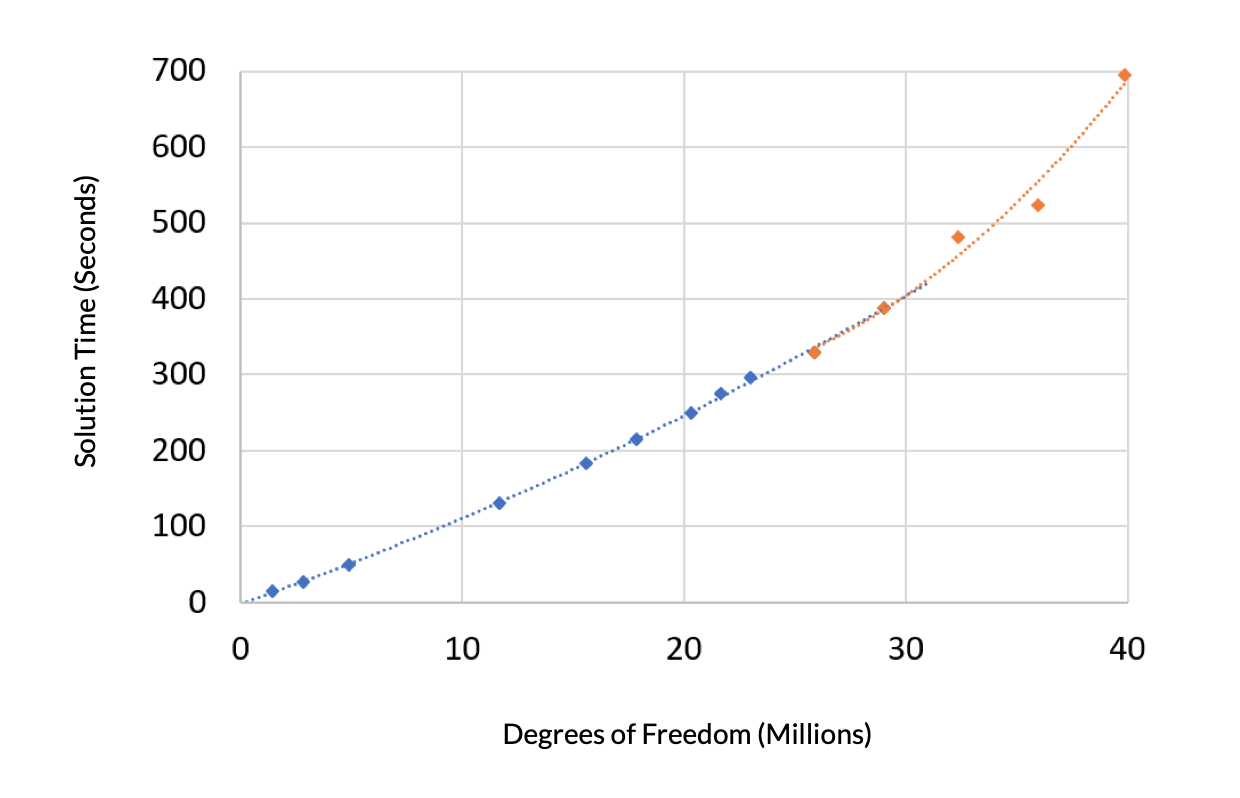
图2.当问题大小大于可用的 RAM 时,求解时间与自由度呈递增关系。
内存需求总是相同吗?
你可能会问,上面这些关于内存需求的数据是否始终正确的呢?当然不是,除了非常相似的问题之外,这些数据几乎没有预测价值。
对模型的 6 种典型修改
对当前的模型做出哪些常见的修改会导致这些曲线向上或向下移动?接下来,我们将介绍几个不同的例子。
1.在时域中求解
相较于求解稳态问题,使用时域求解器求解时域问题需要在内存中存储更多的数据。有关此算法的介绍,请阅读博客:瞬态问题中的自动时步和阶数选择。
2.切换线性求解器类型
上述问题还可以用迭代或直接求解器求解。迭代求解器较直接求解器使用的内存要少得多,尤其是在问题规模增大时。相比之下,直接求解器仅适用于某些问题类型,例如由于材料特性的高对比度导致系统矩阵几乎是病态时,但该矩阵仍能超线性扩展。
3.引入非线性
即使是在单一的物理场中,引入例如使材料特性成为温度的函数等任何种类的非线性,都会导致系统矩阵的非对称性。从而导致内存需求增加。通过 nojac() 算子来避免符号微分,但并不是在所有情况下都可以这样做,因为这可能会对非线性收敛率产生负面影响。
4.改变单元类型
求解三维问题的默认单元类型是四面体单元,但也可以使用其他单元类型,如三角棱柱或六面体。这些单元的单个单元的连续性更好,但会增加内存的使用。另一方面,对于特定的几何结构和问题来说,可以通过手动改变单元类型,因为对于同样的几何结构,这些单元的网格更粗,特别是与几何分割和扫掠网格结合使用时,往往占用的内存更少。
5.改变单元阶次
求解固体传热 时默认的单元阶次是二次拉格朗日。如果网格相同,改变为线性将减少模型中的自由度,同时也将导致每个单元的连续性降低。也就是说,每个单元的各个节点都有较少的相邻节点。对于相同的自由度,这将降低内存使用量。反之,增加单元阶次会产生更大的连通性。对于相同的自由度,这将增加内存的使用量。此外,可以在拉格朗日和巧凑边点单元之间转换,后者每个单元的节点更少。然而,有必要了解的是,改变单元阶次和类型对精度和几何网格划分要求都有影响,这本身就是一个复杂的话题,所以改变默认的单元阶次应该谨慎对待。
6.引入非局部耦合或全局方程
非局部耦合涉及在非相邻单元之间传递信息的任意类型的额外耦合项,通常与全局方程一起使用。使用这些项会影响系统矩阵中的信息量,并经常使问题变为非线性。例如 终端 等某些边界条件可用于涉及电流的问题,并会在底层方程中引入非局部耦合或全局方程。非局部耦合也可以手动实现,博客:计算和控制空腔体积对此进行了讨论。
求解不同的物理场
那么,如果要求解不同的物理场问题呢?上述使用有限元法求解(标量)温度场的示例与传热仿真有关。如果通过有限元法求解不同的物理场,那么可能要求解的是一个矢量场。例如:
- 固体力学
- 流体流动
- 电磁学
- 化学物质传递
- 在求解化学工程问题时,如反应流,自由度的数量与在模型中包括的化学物质的数量成正比。
对于上述每一个物理场,或任何其他通过有限元法求解的物理场,我们不得不再次考虑之前提到的所有要点的影响。那么,如果我们采用的是除有限元之外的其他方法呢?我们可以使用 COMSOL® 中内置的一些接口和方法,比如 粒子追踪 接口求解粒子位置的一组常微分方程(ODE),相较于有限元,它的内存需求和自由度要低得多;射线光学 接口也求解一组常微分方程,并且内存要求与粒子追踪相似。间断伽辽金(dG)方法用于求解电磁波、声波和弹性波模型,相较于有限元方法,它使用的内存非常少;最后是边界元法(BEM),这是一种离散化方法,但是边界的离散而不是体积。边界元法对每个自由度的内存需求远高于有限元法,但对于相同的精度,其自由度需求更少。边界元法在声学、静电学、电流分布、磁静力学 和电磁波中都有应用。
最后,我们不仅可以在模型中包括这些不同的物理场,还可以将它们耦合起来,建立一个真正的多物理场模型。建立多物理场模型时,还必须考虑可能的求解方法,因为这样的模型可以用完全耦合或分离的方法,用直接或迭代的求解器来求解,所有这些都会影响内存需求。下表给出了这些领域中一些典型问题的内存需求的大致情况。
| 物理场 | 每千兆字节的自由度 |
|---|---|
| 固体传热 | 800,000 |
| 固体力学 | 250,000 |
| 电磁波 | 180,000 |
| 层流 | 160,000 |
从这个角度来说,我们可能需要了解内存需求预测的复杂性。不过,从实用性的角度来看,这些信息有什么用呢?对于我们的日常仿真工作来说,只需开展一个比例研究。也就是说先建立一个包含所有物理场、边界条件和耦合的小模型,并使用所需的离散化。从求解开始逐渐增加自由度的数量,同时监测内存需求。这个数据通常是线性的,但有时会与自由度的平方成正比增长,比如使用直接求解器的边界元法时,或者如果有多种非局部耦合时。基于这些信息,我们就可以进一步优化模型的性能。
不同的计算机硬件如何提高模型性能?
现在,让我们回到之前的求解时间与自由度的关系图,讨论可以改变求解时间的 10 种不同的计算机硬件改变。
用固态硬盘代替机械硬盘
当所使用的虚拟内存明显大于物理 RAM 的时候,用固态硬盘代替机械硬盘很重要。用于生成上文示例曲线的计算机包含一个固态硬盘,这对于大多数较新的计算机很常见。相较于固态存储器,带旋转盘和移动读写头的机械硬盘(HDD)所需的求解时间较长。当求解那些内存需求比 RAM 少的模型时,这种选择的影响明显较小。除了固态硬盘之外,一个大容量的 HDD 也是可行的,HDD 主要用于保存模拟数据。
添加更多的内存
只要在所有的内存通道上均衡地添加内存,就能提高使用虚拟内存明显多于物理内存的模型的求解速度。例如,用于这些测试的 CPU 有四个内存通道和 32 GB 内存,每个通道有一个 8 GB DIMM。可以通过添加四个额外的 8 GB DIMMs 进行升级,每个通道一个(因为这台电脑每个内存通道有一个空的第二插槽),或者将所有四个 8 GB DIMMs 换成 16 GB DIMMs。无论哪种方式,重要的是每个通道都要被填满。例如,如果四个通道中只使用了一个,那求解速度就会减慢。
升级到速度更快的双列直插内存模块(DIMMs)
根据 CPU 的情况,有可能升级到支持更高数据传输速率的 DIMM。重要的是,所有的 DIMM 都有相同的速度,因为如果 DIMM 的内存速度不均衡,通常会支持最低速度。
升级到时钟速度更快的 CPU
时钟速度影响到软件的各个方面,速度当然是越快越好。从实用角度看,通常无法仅升级时钟速度而不影响其他硬件配置,因此很难单独评估其改进效果。大多数情况下,我们不得不购买一台新的计算机。然而,随着模型使用更大的内存,以及更多的数据需要在 RAM 中来回传输,模型的性能瓶颈往往是数据在 RAM 内存中的传输速度,而不是 CPU 速度。
升级到有更多内核的 CPU
在保持所有其他因素不变的情况下,升级到更多的内核相当困难。因此,很难确定增加内核数量是否能带来显著改进。在大多数情况下,求解单一模型时,使用超过 8 个内核并无明显优势。如果求解时间由直接线性求解器主导,那么内核更多则获益更多。另一方面,非常小的模型可能在单核上求解得更快,即使有更多的核可用。也就是说,对于较小的模型来说重要的是,并行化有一个计算成本。
另外,在并行运行多项工作时,如当使用 COMSOL Multiphysics 中的批处理 功能时,多核也是有优势的。现在有些 CPU 同时提供 P 核和 E 核,这就需要额外进行性能权衡。
升级到有更大缓存的 CPU
缓存内存总是越大越好,但是缓存的大小与核的数量成正比,所以有最高缓存的 CPU 会有很多的核,价格也相对昂贵。
升级到带更多内存通道 CPU 的计算机
我们有可能买到有两个、四个、六个甚至八个内存通道的单 CPU 电脑。不同通道之间的切换也代表不同级别的处理器之间的切换,而且仅凭硬件规格很难比较它们之间的性能。如果你经常求解非常大的模型或多个模型的并行问题,那么超过四个通道是有必要的。
升级到双 CPU 计算机
支持双插槽操作的 CPU,其每个 CPU 有 6 个或 8 个内存通道,总计有 12 个或 16 个通道,由此这类系统至少有 96 GB 内存,所以这些系统主要用于求解非常大的模型或许多模型的并行操作。
升级到 4 个以上 CPU 的计算机
这种情况非常少,仅考虑需要非常多 RAM 内存(至少 768 GB)的模型。在考虑这样的系统之前,请联系我们的技术支持团队获取个性化的指导。
升级到集群计算机
目前集群计算机的数量已达成千上万台,其中相当多一部分已经被用于运行 COMSOL®。可用的集群硬件系统如此之大,而且变化如此之快,以至于不可能对相对性能做出说明。有一些云计算服务提供商也可以迅速让我们在所选择的硬件上启动一个临时的计算资源,这样就可以在各种硬件上比较相对性能。在求解极其复杂的模型方面,集群的优势在于能够使用域分解求解器。当然,集群对于在一个集群扫描节点内并行求解数百个甚至数千个案例也很有用。
注意:除了所有这些因素外,还要考虑处理器的更新换代和架构。处理器几乎每年都有重大更新,而且每年都有几个小的更新。比较上述不同代处理器的指标相当困难,但一般来说,较新一代处理器的性能优于较旧的处理器。
我应该如何决定购买什么计算机?
在决定购买什么样的计算机方面,首先是选择一个或一组模型,来描述你要做的各种分析。然后,进行扩展研究,确定内存需求,因为仿真求需会增长。当然,我们需要做一点猜测和推断,所以最好高估内存需求。
一旦对所需要的内存量有了一个很好的概念,就可以在最新一代处理器之间决定内存通道的数量。这是我们拥有最大灵活性的地方,所以在这里真正要考虑的是内存的可升级性。如果碰巧我们低估了内存要求,又希望能够轻松地安装更多的内存。例如,用于生成上文数据的计算机有 32GB 内存,安装在有一个有 4 个内存通道的系统上,每个通道有一个 8GB 的 DIMM,每个通道有一个插槽开放,因此,再买 4 个 8GB 的 DIMM 就可以很容易地升级到 64GB 内存。
接下来,在选择处理器方面,要确保处理器架构支持最快的可用内存速度,并在该架构中选择最快的时钟速度。通常在时钟速度和内核数量之间有一个权衡。缓存的大小往往随着内核数量的增加而增加,但是每个内存通道存在两个以上的内核,通常会导致性能与硬件成本之间的受益递减。
还要记住一些其他因素,例如,如果预计虚拟内存使用量较大,就需要一个 SSD 驱动器。至于显卡,这里列出了支持的硬件列表,内存越大速度越快,显卡的显示性能就越好。另外,计算机通常是针对不同市场和价格区间设计的,例如,高端工作型和经济型消费级设备。后者有时会有更好的峰值性能,但在连续多小时或多天运行非常大的模型时,高端工作站别的系统可能更可靠。
还有什么可以提高性能?
你可能想去购买新的硬件来运行你的模型。不过,这样做之前,请考虑一下你所建立的模型的价值。一个有价值的数值模型是你在职业生涯中要运行成千上万种(或更多!)变化的模型。尽可能地提高这些模型的性能将为你节省数周或数月的时间,无论你使用什么硬件都是如此。
将模型分类
为了学习如何让模型运行的更快,无论使用的是什么硬件,我们可以从概念上将模型分为三类。
1.线性稳态
这类模型包括材料属性、载荷和边界条件与解无关的情况。频域和特征值或特征频率模型也可以归入这一类别。对于这些模型,计算时间完全与自由度的数量有关,所以目标应该是在达到预期精度的同时尽可能地减少自由度。
2.非线性稳态
这类模型包括在控制方程中出现非线性项的任何情况,例如在纳维-斯托克斯方程中,或者当材料属性、载荷或边界条件是解的函数时。这类情况的求解是通过重复求解线性问题而找到的。这里,所需的计算时间是线性迭代的成本和非线性问题的收敛率的组合。降低计算成本不仅涉及在达到预期精度的同时保持尽可能低的自由度,而且还涉及提高非线性收敛率。也就是说,减少得到解所需的步骤。减少自由度既影响求解时间,也影响内存使用量,而非线性收敛速率则主要影响求解时间。
3. 瞬态
这类模型通过在离散的时步数上求解一串静止的近似值来计算瞬态解,可能包括也可能不包括非线性项。这里需要关注的是减少离散时步数,以及每个时步数所需的线性化步数,同时有足够精细的网格来求解瞬态场。
有用的仿真技术
虽然每个问题都是独特的,但有一些非常通用的仿真技术是所有的仿真分析人员都应该掌握的,包括:
- 在处理导入的 CAD 文件时,使用特征去除 和虚拟操作 功能近似 CAD 数据,用于创建更简单的几何体,或使用对称性减少 CAD 模型的大小。
- 当处理相对较薄或较小的几何结构时,使用简化的几何结构和可能不同的物理场接口,如结构仿真中壳和梁的例子。或者,使用指定的边界条件,而不是明确地对薄域的几何形状进行建模。
- 在合理的情况下,使用扫掠网格和装配式网格,并充分熟悉手动构建网格的方法。
- 对于非线性稳态问题,理解实现和加速收敛的各种方法。
- 对于瞬态问题,了解提高收敛性的各种方法。
当然,这些只是大体上的描述。有许多特定的仿真技术,可能只在非常窄的范围内适用,但可以让模型运行更高效。学习这些技术,何时以及如何应用它们,是有经验的数值仿真人员的智慧所在。
结语
这篇博客,我们提出了一个看似简单的问题,但在实际回答问题的过程中,触及了比较广泛的话题。最后,我提出一个有点争议性的个人观点。在我看来,试图在更快的计算机上求解更大的模型是一种不得已而为之的计算方法。与其花费大量时间研究硬件配置,不如专注于如何优化模型,使其更小、更高效。当然,终有一天,你或许确实需要投资专业硬件。而当那一刻到来时,你将清楚地知道升级的必要性。希望本文能为你在这一过程中提供一些指导和帮助。
Intel 和 Xeon 是 Intel 公司或其子公司的商标。
Microsoft 和 Windows 是微软公司在美国和/ 或其他国家的注册商标。
COMSOL Multiphysics® 软件的核心功能之一是运行批处理扫描的能力,即在同一台计算机上对同一模型的多个变化进行并行求解,而且这个过程完全是独立工作的。随着更高核数的 CPU 和支持多个 CPU 的计算机的普遍应用,可以使用 批处理扫描 功能显著提升速度。让我们来看看如何操作吧!
批处理扫描简介
任何关注计算机硬件的人都知道,每一代处理器技术都会带来重大改进。在很长一段时间里,计算速度逐年提高,但这种趋势已经停滞不前。现在,计算机制造商倾向于在每个 CPU 中投入越来越多的内核。
默认情况下,COMSOL® 软件会使用所有可用的内核求解每个模型,但这并不总是有益的。许多 COMSOL Multiphysics 模型只能部分并行化,甚至是完全串行的,因此为单个模型配备更多的节点本身可能不会带来速度的提高,特别是在模型对内存的要求相对较小的情况下。
实际上,这意味着新一代多核 CPU 运行单个相对较小的 COMSOL Multiphysics 作业的速度并不一定比老式 CPU 快很多,但它们能够同时运行更多的作业。这使我们在求解同一模型的多种变化的情况下有了明显的净改进,比如扫描几何尺寸、运行不同的工作条件或工作频率。批处理扫描 功能就是为这种情况准备的。
在开始使用批处理扫描 接口之前,关于它的操作有一些重要的事情需要了解。首先,批处理扫描 可以启动多个完全独立的 COMSOL Multiphysics 流程或作业。这些作业不知道其他作业在做什么。如果一个案例失败了,它不会影响其他任何案例,但是也无法在案例之间传递结果。
其次,每个作业都会将包含该作业结果的文件写入磁盘,并且可以选择将所有这些结果组合回原始文件中。
第三,在运行这些作业时,软件会自动在可用的计算内核之间分配并行作业。
最后,批处理扫描 是 COMSOL Multiphysics 的核心功能之一。它适用于在一台计算机上运行(尽管很可能是一台具有多个 CPU 的计算机),并且适用于任何许可证类型。它是集群扫描 功能的补充(仅适用于浮动网络许可证),但提供了类似的功能,还可以在集群的不同计算节点之间额外地分配作业。
批处理扫描的设置
为了使用批处理扫描 功能,我们必须首先在模型开发器的显示更多选项 对话框中启用批处理 和集群 选项。该对话框如下面的屏幕截图所示。
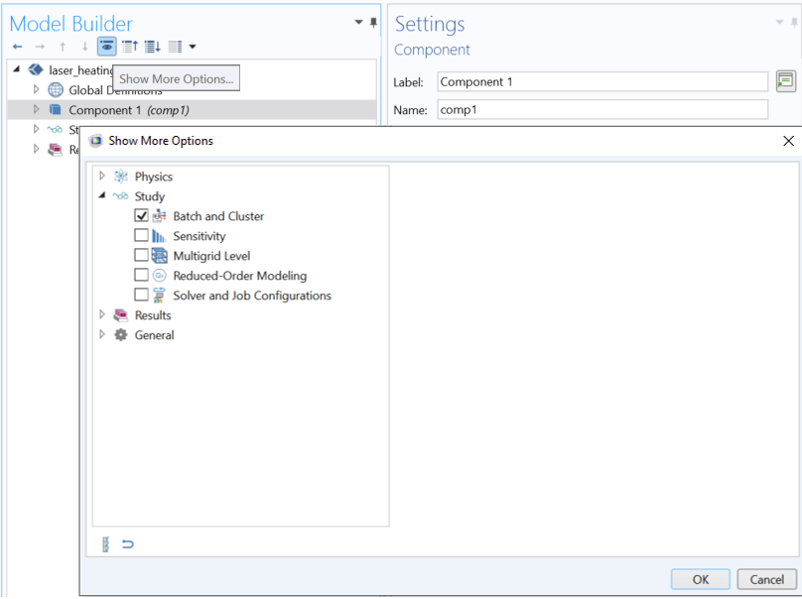
模型开发器中的 显示更多选项对话框。
启用这项功能后,就能够将批处理扫描 功能添加到研究 分支。这项功能将始终存在于研究 的最顶部,并且可以被认为是一个 for 循环,控制着该 研究 分支中存在于其下的所有其他研究步骤。
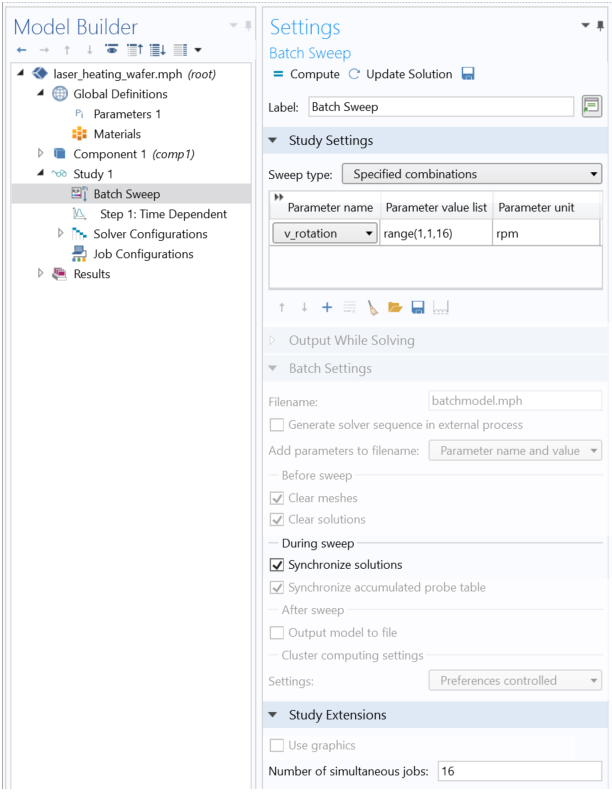
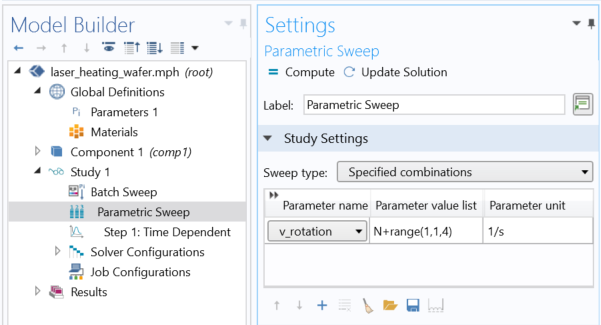
相关的 批处理扫描功能设置。
批处理扫描 的用户界面如上图所示,相关功能被突出显示。首先,在最顶部,我们指定要扫描参数的名称以及要研究该参数的数值。接下来,启用同步解 选项会将所有结果组合回一个文件中。如果不启用这个选项,那么批处理扫描将只写入一组不同的文件;扫描中的每个参数都有一个。(这实际上可能是一个有吸引力的选择,因为可以快速获得非常大的文件,因此如果想在每个文件中保存更少的数据,可能值得考虑。)最后一个关键设置位于窗口底部:并发作业数,它决定了并行运行的作业数量。
此外,请记住,批处理扫描 可以包含任何其他类型的扫描:参数、函数、材料、辅助 或频率 扫描,因此我们可以使用单个批处理扫描 作业解决任意组合的情况。
那么,我们实际上应该并行运行多少个作业?这是我们要研究的下一个问题。
COMSOL Multiphysics® 可以利用多少个核芯并行的批处理?
正如你可能已经猜到的那样,这个问题的答案取决于硬件和型号。
就模型类型而言,批处理扫描 的理想情况是内存需求较小但求解时间相对较长的模型。这种模型的一个很好的例子是硅晶片激光加热。该模型解决了激光热源在旋转硅晶片上移动时温度变化。它只有大约 2000 个自由度,但在经典的台式计算机上求解大约需要一分钟的时间。我们可以在这个模型中扫描许多不同的参数,所以让我们看看这个模型的性能如何与典型现代台式计算机上的作业并行性相匹配。
我们将展示的结果是在带有 32 GB RAM 的 Intel® Xeon® W-2145 8 核处理器上生成的,这是 COMSOL 硬件建议中建议的典型中端计算机。在这个硬件上,求解测试案例模型大约需要一分钟。如果我们对模型的 16 种变化进行参数化扫描,求解时间会随着求解的不同案例的数量呈线性增长。如果我们还使用批处理扫描 ,可以研究在此硬件上并行运行 2、4、8 甚至 16 个作业,每个批处理作业都包含一个顺序参数扫描,如下面的屏幕截图所示。
显示嵌套扫描的屏幕截图。在这个示例中,外部 批处理扫描扫描了 N = 0、4、8、12,而内部扫描总共求解了 16 种情形。
下面的结果是求解 16 种情形所需的时间和相对加速。
| 参数化扫描 | 批处理扫描 + 参数扫描 | ||||
|---|---|---|---|---|---|
| 16 种情形 | 2 个并行作业 (每个作业 8 种情形) | 4 个作业 (4 种情形/作业) | 8 个作业 (2 种情形/作业) | 16 个作业 (1 种情形/作业) | |
| 时间(秒) | 1010 | 620 | 416 | 305 | 267 |
| 加速 | 1 | 1.6 倍 | 2.4 倍 | 3.3 倍 | 3.8 倍 |
从这些数据中可以看出,当我们同时运行更多作业时,会获得更多的加速。最有趣的是,我们可以在 8 核机器上并行求解 16 个作业,并且仍然可以观察到加速。换句话说,这个 CPU 的每个内核实际上可以同时处理两个 COMSOL® 作业,至少在求解这个特定模型时是这样。在这台机器上启用了超线程,虽然这不会加快求解本身的速度,但文件打开和关闭以及其他操作系统进程都受益于启用超线程。并行运行这么多案例确实会减慢求解每个案例所需的时间,但所有 16 个案例所花费的总时间会更少。
如果我们尝试并行运行更多作业,讨论在内存上会发生什么也很有趣。这个模型每个批处理作业需要大约 1 GB 的内存,而文中使用的测试计算机有 32 GB 的内存,所以 16 种并行情形是没有问题的。但是,如果我们上升到 32 种并行情形,可能会超过可用的内存,这将导致速度变慢,不管有多少个内核。当然,在具有更多内存、更多内核和多个 CPU 的计算机上,可以获得更多的相对加速。此外,COMSOL Multiphysics 不限制可以在一台计算机上处理的内核或 CPU 的数量。
这些数据看起来相当不错,这时你几乎肯定会问自己是否总是能得到这么好的结果。不幸的是,答案是:不一定。求解的模型越大,我们看到的加速就越少。对于非常大的模型,如果并行运行作业,整体速度会变慢。但是,对于很多模型,尤其是大多数二维模型和较小的三维模型,在多核、多 CPU 计算机上使用批处理扫描 时,您可以合理地期待类似的改进。因此,批处理扫描 功能可以有力的推动对这类硬件的投资。另外,我们之前的博文中讨论的批处理扫描 功能还有很多其他功能。请记住,这是 COMSOL Multiphysics 的核心功能,适用于所有许可证类型!
Intel 和 Xeon 是英特尔公司或其子公司的商标。
我们已经确定数字孪生概念可不仅仅只是一种炒作。在本篇博客文章中,我们将讨论如何结合使用高保真多物理场模型与轻量化模型和测量数据,来创建可用于理解、预测、优化和控制真实系统和真实系统模型的数字孪生模型,下面我们以混合动力汽车的电池组为例进行说明。
数字孪生概念
传统的基于模型的设计需要进行模型验证和确认,这可以用来优化设备或过程的设计或运行。我们通常通过比较实验结果和模型结果并进行参数估计来验证模型。
数学建模和仿真广泛用于设备和过程设计。
数字孪生(也称为虚拟孪生)的概念涵盖了上述基于模型设计的验证和确认步骤。不同之处在于,数字孪生意味着模型与设备或过程之间的信息传递更加紧密,而且通常是实时性的。数字孪生概念可用于设备或过程的设计、制造和运行阶段,目的是基于虚拟空间中的模型来理解、预测、优化和控制真实系统。我们可以认为数字孪生模型适用于相对复杂且成本较高的系统。我们不太可能为传统汽车的每根排气管构建数字孪生模型或管理数字孪生模型实例,这可能不会带来投资回报。然而,电池组是一个成本相对较高的系统。
在本篇博客文章中,我们举例说明了数字孪生模型在 混合动力或电动汽车电池组的设计和运行阶段的应用。
电池组的数字孪生模型
下图显示包含真实空间中物理设备的数字孪生模型概念:一个带有传感器和控制系统的电池组。虚拟空间包含模型,本例中为电池组模型。数据和信息的传递将真实空间与虚拟空间联系起来( 参考文献 1 )。

混合动力汽车的电池组体现了数字孪生模型概念。
多物理场、多尺度和轻量化模型
虚拟空间包含真实过程的丰富表示,以非常高的保真度虚拟地模拟真实过程( 参考文献 2 )。不仅如此,当需要较小时间尺度的结果时,轻量化模型还可用于更快的交互,我们可以不断地校准这些轻量化模型,得到高保真的模型。
在电池组案例中,数字孪生模型可以是同样包含历史数据的 电池组多物理场和多尺度系统模型,轻量化模型可以是 电池组的集总和等效电路模型。历史数据可以包含特定电池组的测量数据,包括:
它还可能包含来自同一模型的其他电池组的数据。特定电池组的数字孪生模型可称为该电池组模型的数字孪生模型实例。

数字孪生模型由一系列不同的模型构建而成,这些模型以极高的保真度一同模拟电池组的特性。
借助这些模型,我们可以使用测量数据和报告中的数据精确地表示电池组的内部条件,并提取模型中的参数。然后将这些模型用于预测电池组的运行情况,并计算可用于电池组控制的控制参数。
信息处理意味着发回控制参数,这些参数使电池组的运行适应电池的状态、驾驶员的驾驶状况以及当前的运行和驾驶条件,它还可以向电池组和驾驶员发回有关预计电池组未来运行状况和特性的报告。例如,如果存在温度过高的风险或者在电池的特定充电状态下,它可以发送在充电期间(制动期间)暂时限制最大电流的参数,还可以检测到异常电池组中的电池,并将其与电路断开。
机器学习、云计算和物联网
虚拟空间中的复杂模型可能需要功能强大的计算机才能足够快地生成实时有用的结果。这意味着数字孪生模型的大部分性能可能是由通过功能强大的服务器(例如,使用云计算)远程运行的进程提供的,而另外一些进程可能在汽车中安装的控制装置中本地运行。
例如,上述轻量化模型可直接用于电池组中的控制装置。为了保持这些轻量化模型的准确性,我们可以将控制参数与较大时间尺度上计算的更丰富模型的预测数据和结果进行比较,从而实时更新控制参数。更丰富的模型可以对电池的温度分布、充电状态以及其他电化学和物理参数进行详尽的物理描述。因此,数字孪生模型可以在不同组件部署于不同平台和位置的系统中产生。

部署在不同位置的多个组件和模型可能有助于创建数字孪生模型。
数字孪生模型与其实际对应物通常不是孤立的系统。在大多数情况下,它们是更大系统的一部分,这个系统可能还包含其他设备及相应的数字孪生模型。此外,为了优化、控制和预测设备的各个方面,真实设备可能具有多个数字孪生模型,称为数字孪生模型集合体。
举例来说,如果电池组的某些零件容易发生疲劳,我们可能想要为电池组的结构性能创建一个数字孪生模型。这可能只在更大的时间尺度上影响电池组的运行,因此这种数字孪生模型可以更松散地耦合到模拟电池组电性能的数字孪生模型中。电池组的数字孪生模型也可与混合动力汽车的发电机、电动机和内燃机的数字孪生模型交换信息。

真实系统可以与许多数字孪生模型互动,而这些数字孪生模型之间也可以互动。
较大系统中的不同部分和它们的数字孪生模型可能需要相互通信。此外,数字孪生模型可能需要从安装在不同物理位置的传感器和设备获取数据。 物联网(IoT)及相关技术可用于传感器、设备和产生数字孪生模型的计算机系统之间的通信。
机器学习(有时也称为人工智能或 AI)算法可用来训练数字孪生模型,以决定何时应查询不同设备或其他数字孪生模型的数据,何时应更新不同的控制参数,以及何时应更新数字孪生模型和真实系统的报告。因此,数字孪生模型、云计算、物联网 和人工智能 等术语是高效开发、设计、制造和运行高成本电池系统(如安装在电动汽车上的系统)的重要概念。
如何将 COMSOL Multiphysics® 模型并入数字孪生模型?
工程技术人员和科研人员可以使用 COMSOL Multiphysics® 软件创建极其精确的多物理场和多尺度模型。此外,该软件还能轻松组合轻量化模型,并根据较丰富模型预测的高保真特性持续更新轻量化模型。我们可以使用最先进的参数估计和优化方法不断验证模型。这种模型是数字孪生模型的关键组成部分。
为了使用 COMSOL Multiphysics 模型创建数字孪生模型,我们必须允许这些模型不断接收来自外部系统的测量数据和报告,然后将预测和控制参数传回该系统,最简单的方法是使用与 Java® 结合使用的 COMSOL API。
举个例子,COMSOL Multiphysics 模型文件可能包含代表数字孪生模型不同方面的多个模型组件。在电池组示例中,这些模型组件可以是三维高保真模型组件、微观尺度的精细电化学模型组件以及用于快速交互的集总模型组件。当模型保存为 Java® 模型文件时,我们可以从 Java® 程序中访问所有这些组件。包含在这种程序中的 Java® 模型文件可以与外部系统通信,比如通过使用动态链接库文件(dll 文件)来实现。借助 Java® 生态系统,你还可以将虚拟空间实现为一个网络服务(例如,运行在 Tomcat 内部的基于 Java® 的网络服务),该服务可以提供代表性状态传输(representation state transfer,简称 REST)API,用于与真实空间通信。
在真实空间与虚拟空间之间建立连接的另一种方法也可以通过 COMSOL Server 中的 App 和使用 COMSOL Compiler 创建的编译 App 获取。这里的限制在于,在 COMSOL Server 或已编译 App 中运行的仿真在执行过程中无法更新。但我们可以启动或重新启动执行程序,以根据事件触发的变化来更新真实物理设备和数字孪生模型;例如,文件中的更改、传感器触发的命令或操作员触发的事件。真实空间与虚拟空间之间的数据和控制参数可作为由这些事件触发的命令的结果来回发送。
中的 App 和使用 COMSOL Compiler 创建的编译 App 获取。这里的限制在于,在 COMSOL Server 或已编译 App 中运行的仿真在执行过程中无法更新。但我们可以启动或重新启动执行程序,以根据事件触发的变化来更新真实物理设备和数字孪生模型;例如,文件中的更改、传感器触发的命令或操作员触发的事件。真实空间与虚拟空间之间的数据和控制参数可作为由这些事件触发的命令的结果来回发送。
结束语
数字孪生模型的概念在军事和空间应用之外刚刚开始变得切实可行,并且备受青睐。分析人员提出的一个问题是缺乏模型,以及缺乏产生高保真预测所需的建模和仿真知识( 参考文献 3 )。
许多数字孪生模型仅仅依靠对输入数据的统计处理以及对历史数据的查表来创建数字孪生模型。其缺点在于,我们很难了解和理解设备或过程中的真实情况。对于特定制造商的大量设备或过程,我们还需要非常大量的可靠数据;而对于大批量生产的成本较低的产品来说,这可能是一种可选的方法。
相比之下,多物理场模型在得到验证后即可用最少的数据在广泛的运行范围内保持精确。出于这些原因,包含某种基于模型描述的数字孪生模型是理想之选。对于电池组等高成本产品,尤其需要使用可靠的多物理场模型。
偏微分方程(Partial differential equation,简称 PDE)是表述物理定律的最精确方法( 参考文献 4)。借助 COMSOL Multiphysics,我们能够使用基于 PDE 的多物理场模型,根据最精确的描述创建数字孪生模型。
参考文献
- M. Grieves, “Digital Twin: Manufacturing Excellence through Virtual Factory Replication,” Michael W. Grieves, LLC, 2014.
- E. Glaessgen and D. Stargel, “The Digital Twin Paradigm for Future NASA and U.S. Air Force Vehicles,” 53rd Structures, Structural Dynamics and Materials Conference, 2012.
- J. Voskuil, “Model-Based — The Digital Twin,” Jos Voskuil’s Weblog, 2 July 2018; https://virtualdutchman.com/2018/07/02/model-based-the-digital-twin/.
- R. Feynman, Differential Calculus of Vector Fields, The Feynman Lectures on Physics, 1963–1965.
Oracle 和 Java 是 Oracle 和/或其附属公司的注册商标。
在之前的一篇博客文章中,我们解释了如何在 COMSOL Multiphysics® 软件中直接从 COMSOL Desktop® 环境实现在集群上运行作业,而无需与 Linux® 操作系统终端进行任何交互。由于这种终端有时需要使用者具有足够的操作技能,因此能够直接从图形用户界面启动集群作业便是 COMSOL® 软件最有用的功能之一。欢迎了解更多强大功能……。我们首先来看看集群扫描 节点。
什么是集群扫描节点?
将参数集计算并行化的一种方法是将参数化扫描与集群计算 节点结合使用。在执行此操作时,你将创建一个跨越多个节点的大型集群作业。添加的节点越多,并行计算的参数值就越多(当然,前提是参数的数量多于节点数)。
集群示例。
不仅如此,你还可以使用集群扫描 节点将计算并行化,该节点设计用于将一个参数化扫描拆分成多个集群计算作业。在集群扫描 节点中定义一组参数,对于每个参数值,系统都会将单独的批处理作业发送到集群队列。计算完成后,COMSOL Multiphysics 会将结果整合回主进程。
你甚至还可以通过这种方式嵌套参数化扫描,将集群扫描与“标准”参数化扫描相结合。你可以决定为哪些参数启动单独的作业,以及想要将哪些参数保留在作业“内”。
总而言之,集群扫描 节点是 COMSOL Multiphysics 为你提供的强大工具,可以帮助你实现对建模过程的完全控制。
请注意,你需要拥有“网络浮动许可证”(FNL)才能使用集群扫描。此外,建议你熟练掌握博客文章 COMSOL Desktop® 环境如何实现在集群上运行中讨论的设置,如果你按照该篇文章中的步骤操作并保存设置,这些设置将自动应用于集群扫描 节点。
何时使用集群扫描节点
现在,你已经知道什么是集群扫描 节点,你可能还想要了解以下两点:
- 我应该在什么时候使用它?
- 此节点在什么情况下优于集群计算 节点?
对于上述问题,常见的第一种情况是,你有一个参数集但不知道模型是否收敛,或者是否对所有参数组合都有效。参数集可以控制几何结构,在采用某些值时,几何结构可能会导致求解或网格划分失败。如果用参数化扫描计算模型,COMSOL Multiphysics 将在第一个失败的几何结构上取消计算,即使后面的几何结构都能成功计算也将如此。将计算过程拆分为多个单独的作业后,你便可以开始针对每个参数值进行计算。
另一种情况是,涉及的参数值数量太大,单个集群作业无法完成计算。如果你有用于控制频率、几何、材料、边界条件等的参数,并希望得到所有可用组合的结果,则需要进行大量的 计算。如果你将所有计算都放入一个大型作业并将其发送到集群,那么几乎可以肯定会引起集群管理员和同事们的强烈不满(稍后会详细说明)。
好消息:通过使用集群扫描 节点,你可以将潜在的大型作业拆分成多个小作业。为此,除了集群扫描 节点外,还需将参数化扫描 节点添加到模型中。以这种方式设置模型会创建嵌套参数化扫描(类似于编程中的嵌套 for 循环)。请继续阅读本文,了解详细的操作步骤。我们在本篇博客文章中引入了一个简短的教程。
关于集群扫描 节点,还有一点需要注意:你可以使用它来潜在地增加集群上作业的吞吐量。
使用集群扫描优化调度
上文中我们提到了集群管理员的不满,想必你希望了解其中的原因吧。计算时间是高性能集群的宝贵资源,因此,大多数集群都实施了某种队列或调度系统。如何处理大型作业取决于集群管理员,根据经验,大型作业意味着需要长时间的等待。原因何在?大型作业会占用大量的计算资源,并且可能需要很长时间才能完成。因此,为了不影响其他用户作业的正常运行,为大型作业分配的优先级就会比较低。当然,这一切都取决于集群管理员如何配置调度程序;也就是说,这需要视实际的情况而定。
这与集群扫描 节点有什么关系呢?假设你可以访问一个集群,在这个集群中很难安排大型作业,但很容易安排小型作业,因为它们会填充调度程序中的空隙(未使用的集群节点是计算成本较高的集群节点)。你可以使用集群扫描将大型作业拆分成多个小型作业。
我们通过一个例子来看一下:你可以启动 8 个作业,让每个作业使用 1 个节点来计算它们自己的 100 个参数值的集合,而不是在 8 个节点上启动 1 个大型作业来并行计算 800 个参数值。随后这些作业将被单独调度,小型作业可能比大型作业完成得更快,具体取决于集群的设置。
设置集群扫描和嵌套参数化扫描
如果你有批处理扫描和集群计算 节点的使用经验,那么使用集群扫描 节点会很轻松。(请查看博客文章“ 强大的批处理扫描功能”和 “ 批处理扫描中任务并行的附加值”,找到有关如何设置批处理扫描的描述)。
为了演示如何设置纯集群扫描和嵌套参数化扫描,我们来看看我最喜欢的示例模型:参数化的热微执行器(这是我最喜欢的模型,原因是其中演示了 COMSOL® 软件的多物理场功能)。由于这是一个参数化模型,因此我们很容易向其中添加参数化扫描和集群扫描。
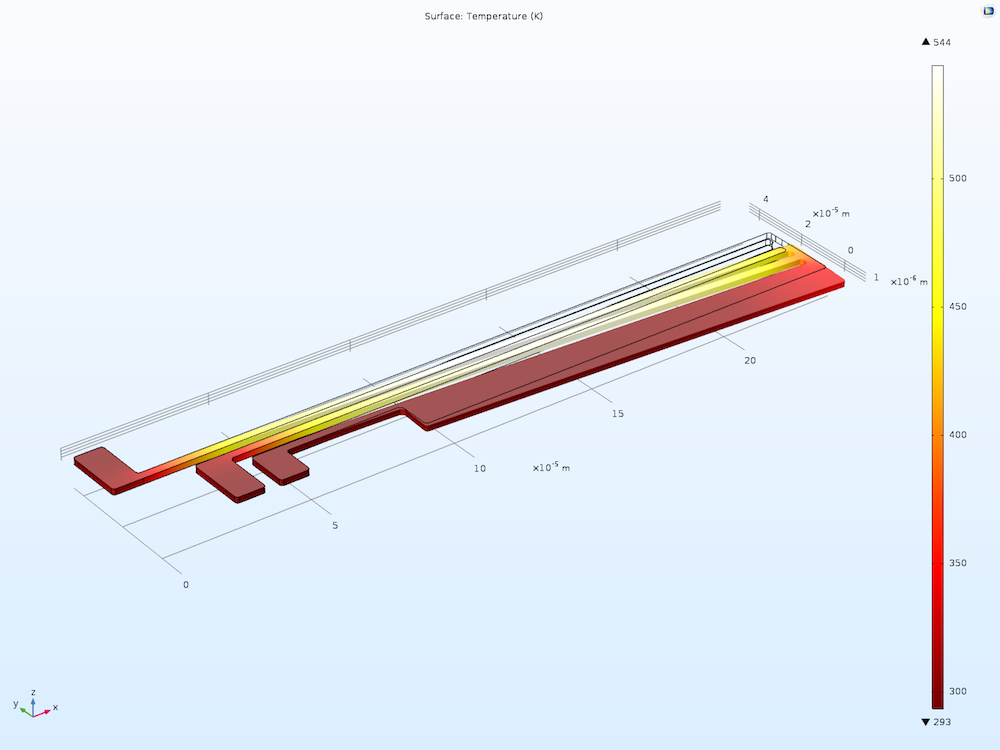
微执行器的焦耳热建模。电流流过两臂,导致它们发热。随后,热膨胀使执行器发生弯曲。
添加集群扫描
我们首先添加一个基于执行器长度参数 L 的集群扫描。为此,首先右键单击研究1,然后单击集群扫描。此操作将添加一个节点,你可以在其中进行集群设置,具体操作请参见这篇关于从 COMSOL Desktop® 运行集群的博客文章中的说明。(如果你还没有看过这篇文章,现在不妨先读一读。)
接下来,你可以在研究设置 窗口中添加要扫描的参数。单击加号并在下拉列表中选择参数 L。然后在参数值列表 编辑框中输入(例如)“100 170 240 310”。在参数单位 编辑框中,输入“um”(微米)。
如果你要将结果引入主模型,请确保选中同步解 复选框。这样,你就可以得到所有结果,并将其用于进一步分析和后处理。
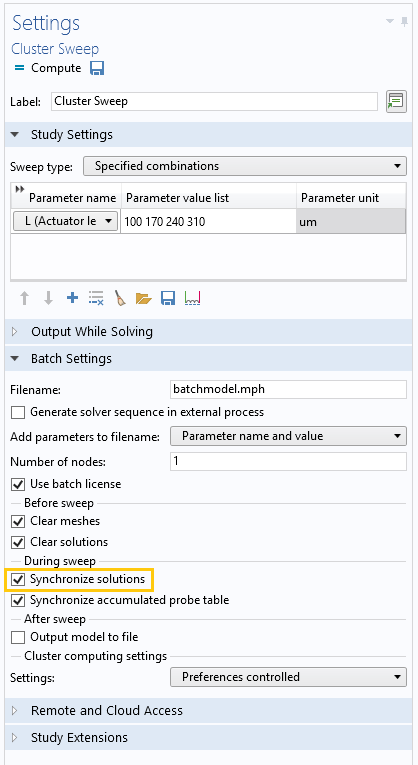
在模型中添加集群扫描。
现在我们已经创建了集群扫描,它基于微执行器的长度进行循环。假设集群设置正确无误,我们现在需要做的就是单击计算,然后将单独的作业发送到集群。
添加嵌套参数化扫描
现在,我们创建一个嵌套参数化扫描,这样我们的每个集群作业本身都包含一个参数化扫描。为此,我们添加一个基于电压参数 DV 的参数化扫描,具体步骤如下:
- 右键单击研究1,然后单击参数化扫描,此操作将添加一个节点,你可以在其中设置参数化扫描
- 在研究设置 窗口中,单击加号,然后在下拉列表中选择参数 DV
- 在参数值列表 编辑框中输入“1 2 3 4 5”
- 在参数单位 编辑框中输入“V”
- 单击计算,COMSOL Multiphysics 将为你调度作业
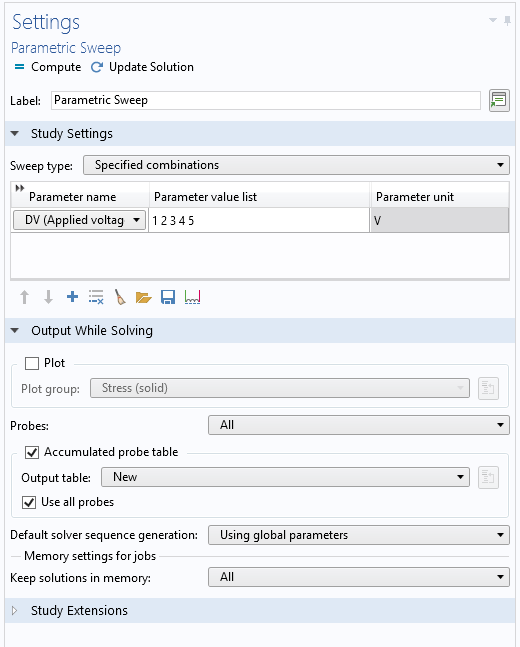
在模型中添加参数化扫描,从而创建嵌套参数化扫描。
你可以等待作业完成(其状态显示在外部进程 窗口中),也可以从进程中分离,然后保存模型,并关闭 COMSOL Multiphysics,让作业自行运行。当你返回工作站时,只需要打开保存的模型并重新连接,软件就会像使用常规集群计算 节点一样处理结果。这一工作流程对于通宵仿真来说堪称完美!
结语
在本篇博客文章中,你不仅学习了如何使用集群扫描 节点对集群上的并行参数计算进行优化,还学习了如何针对不同的情况选用最佳的方法,作为额外的收获,你还知道了如何避免引起系统管理员的不满。
与一般的集群计算一样,你必须根据要计算的模型来决定采用何种方法。为了明白何时使用集群扫描和分布式参数化扫描,你需要在模型和集群上尝试这两种方法。无论何时,要掌握一项技能,都必须进行测试!
如上所述,你需要 FNL 才能使用集群扫描,这是因为此功能是基于网络的技术。
后续操作
如果你想要了解更多关于集群扫描 节点的信息,可以单击下面的按钮联系我们。
Linux是Linus Torvalds在美国和其他国家/地区的注册商标。
在高性能计算(HPC)硬件上运行 COMSOL Multiphysics® 软件对许多类型的分析都非常有利,这是创建集群计算 节点的主要原因之一,该节点有助于将 COMSOL® 软件与任何类型的 HPC 基础设施无缝集成,同时保持图形用户界面的便利性。在本篇博客文章中,我们将学习如何直接从 COMSOL Desktop® 图形环境在 HPC 硬件上远程运行大型仿真。
什么是集群计算?
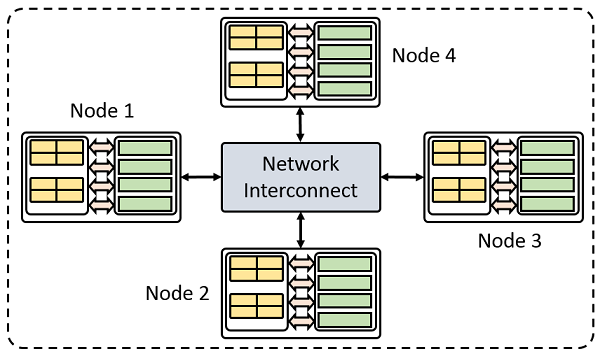
HPC 硬件最常见的类型是集群;它是通过网络连接的一组独立计算机(后者通常称为节点)。即使只有一台专用的仿真机器,你也可以将它视为一个单节点集群。
在 COMSOL Reference Manual 中,还将单个 COMSOL Multiphysics 进程称为节点。这种区别无关紧要,但在需要对二者进行区分时,我们会将计算机称为物理节点或主机,将 COMSOL Multiphysics 程序的实例称作计算节点或进程。
包含四个计算节点的集群示例。
我们要在集群上执行的工作被捆绑成原子单元(称为作业),并提交给集群。这种情况下的作业是通过 COMSOL Multiphysics 运行的研究。
向集群提交作业时,集群会执行两项操作:
- 决定哪些节点运行哪些作业,以及何时运行
- 限制对节点的访问,使多个作业之间不会相互干扰
这些任务分别由称为调度程序 和资源管理程序 的特殊程序执行,由于大多数程序都是同时执行两个任务,因此这两个术语可以交替使用,本文中我们使用前者。
请注意,在提交给集群的脚本中,可以使用 comsol batch 命令(Linux® 操作系统)或 comsolbatch.exe 命令(Windows® 操作系统)提交 COMSOL Multiphysics 作业。如果你熟悉基于控制台的集群访问,你可能更喜欢这种方法。有关更多信息,请参见 COMSOL 知识库文章“在集群上并行运行 COMSOL® ”。
在接下来的章节中,我们将探讨如何使用集群计算 节点从 COMSOL Desktop® 图形界面提交和监控集群作业。
从简单模型开始测试添加集群计算节点
每当我想为尚不熟悉的集群配置集群计算节点时,常常喜欢从简单的母线板模型入手。这个模型只需几分钟即可完成求解,并支持任意类型的许可证,这使集群计算功能的测试变得非常便捷。
为了在集群上运行母线板模型,我们将集群计算节点添加到主研究中。不过,我们需要先启用高级研究选项。为此,我们可以激活首选项 中的选项,也可以单击“模型开发器”工具栏中的显示 按钮。
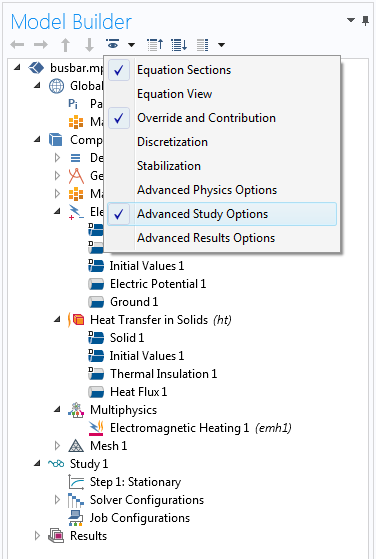
激活高级研究选项以启用 集群计算 节点。
现在,通过右键单击“研究”并选择集群计算,可以将集群计算 节点添加到任何研究中。
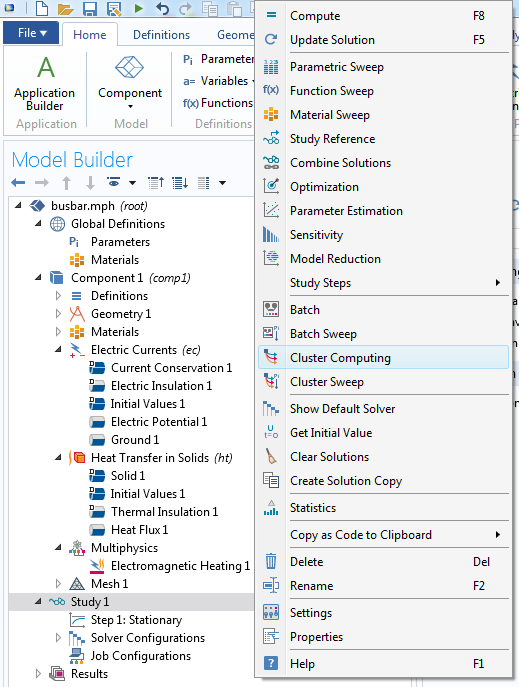
右键单击“研究”节点,然后从菜单中选择 集群计算, 将其添加到模型中。

集群计算节点的默认设置。
如果找不到集群计算节点,可能是你的许可证未启用集群(如 CPU 许可证和学术类课堂许可证套装)。在这种情况下,请联系销售代表询问许可证选项。
集群计算节点的设置
使用集群计算节点最复杂的部分是找到正确的设置并首次使用它。一旦能够在集群中成功地运行这个节点,即可在其他仿真中轻松地对这些设置进行微调。
为了将设置存储为默认选项,你可以在多核与集群计算 和远程计算栏的首选项下更改设置。此外,你也可以将默认设置直接应用于集群计算节点,然后单击“设置”窗口顶部的保存图标。强烈建议你将这些设置存储为默认选项,这样,你就不必为下一个模型再次键入任何内容。
讨论集群计算节点的所有可能设置不在本篇博客文章的范围内,因此我们将重点讨论一个典型的设置。请参阅COMSOL Multiphysics Reference Manual获取更多信息。在本篇博客文章中,我们假设:
- COMSOL Multiphysics® 在本地 Windows® 机器上运行,我们要将作业提交到远程集群
- 集群在 Linux® 系统上运行,并安装有 SLURM® 软件作为调度程序
这些设置如下方屏幕截图所示:
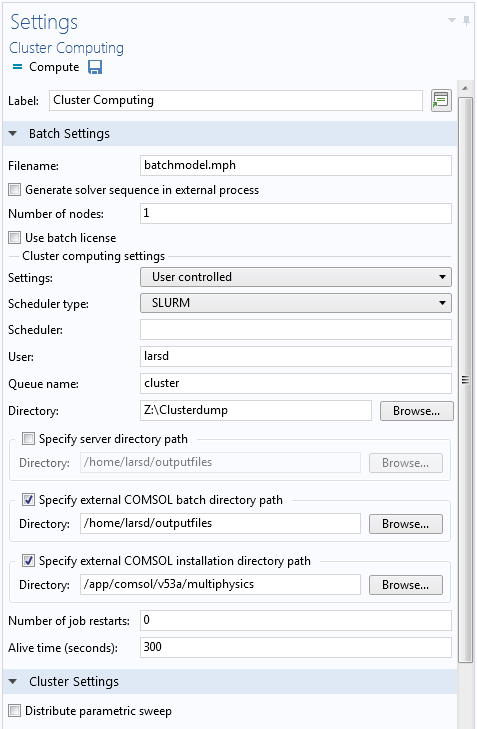
首先,我们来看看集群计算设置栏。由于集群使用 SLURM® 软件作为调度程序,因此我们将调度程序类型设为“SLURM”。以下选项特定于 SLURM® 类型的调度程序:
- 调度程序留空,指示 SLURM® 软件仅使用当前可用的调度程序
- 用户是我们的用户名,可以留空以使用我们登录集群所用的用户名
- 队列名称是要向其提交作业的队列名称
本例使用的机器上有两个队列:“cluster”用于多达 10 个物理计算节点的作业,每个节点的 RAM 为 64 GB;“fatnode”用于 256 GB 的单个节点。每个集群都有不同的队列,你可以询问集群管理员可以使用哪些队列。
下一个编辑框标为“目录”,这是作业完成后求解的 COMSOL Multiphysics 文件在本地计算机上的保存位置,也是 COMSOL® 软件存储任何中间文件、状态文件和日志文件的位置。
接下来的三个编辑框用于指定集群上的位置。请注意,目录是 Windows® 路径(因为这里我们使用的是 Windows® 计算机),但这三个栏的位置是 Linux® 路径(因为我们的集群使用 Linux® 系统)。请确保路径类型与本地和远程端的操作系统相匹配。
服务器目录 指定在客户端-服务器模式下,从 COMSOL Multiphysics 会话中使用集群计算时,文件应存储的位置。从本地机器执行集群计算时,不使用此设置,因此我们将其留空。然而,我们确实需要外部 COMSOL 批处理目录,这是仿真过程中集群上保存模型文件、状态文件和日志文件的位置。对于这些路径,请确保选择一个已经存在并且您有写入权限的目录;例如根目录下的某个位置。(请参阅上一篇有关使用客户端-服务器模式的博客文章,获取更多详细信息)。
COMSOL 安装目录 一目了然,应该包含 folders bin、 applications 等文件夹,默认情况下,通常类似于“/usr/local/comsol/v53a/multiphysics/”,但很明显取决于 COMSOL Multiphysics在集群上的安装位置。
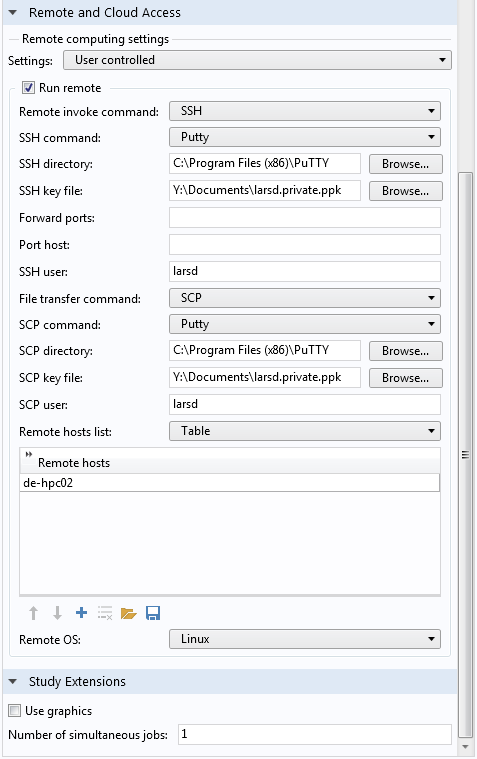
远程连接设置。
下一个重要的栏是远程和云访问,这是我们指定如何在本地计算机和远程集群之间建立连接的位置。
为了从 Windows® 工作站连接到 Linux® 集群,我们需要第三方程序 PuTTY 作为 COMSOL® 软件的 SSH 客户端。请确保 PuTTY 已安装并可以使用它与集群连接。此外,还要确保使用一个公私密钥对来设置无密码身份验证。网上有许多相关教程,你也可以求助于集群管理员。完成此操作后,输入 PuTTY 的安装目录作为 SSH 目录,并在 SSH密钥文件 中输入无密码身份验证产生的私钥文件。将 SSH用户 设为你在集群上的登录名。
SSH 用于登录集群并运行命令,SCP 用于文件传输(例如,向集群传入或传回模型文件)。PuTTY 对 SCP 和 SSH 使用相同的设置,因此只需从 SSH 复制设置即可。
最后,在远程主机 下输入集群的地址,它可以是主机名或 IP 地址。还请记得将远程操作系统 设为集群上的正确操作系统。
完成上述操作后,你可以单击“设置”窗口顶部的保存 图标,下次要运行远程集群作业时,可以从这些设置开始操作。
测试集群设置是否有效的另一种可行方法是使用 COMSOL Multiphysics 5.3a 版提供的集群设置验证 App。
在集群上运行研究
每次运行研究时更改的设置包括模型名称和要使用的物理节点数量。当你单击运行研究后,COMSOL Multiphysics 开始向集群提交作业。第一步是不可见的,涉及运行 SCP 将模型文件复制到集群。第二步是通过向调度程序提交作业开始仿真。此阶段开始后,外部进程 窗口会自动出现,并通知你集群上仿真的进度。在这个阶段中,COMSOL Desktop® 被锁定,软件忙于跟踪远程作业。


在外部进程窗口中跟踪远程作业的进度,从调度作业(顶)一直到完成作业(底)。
这个过程与批处理扫描节点的工作方式非常相似。事实上,你可以通过使用批处理扫描功能来识别外部进程窗口。就像使用批处理扫描一样,我们可以通过单击外部进程窗口下方的脱离作业按钮,将 GUI 从远程作业中分离出来,从而重新对其进行控制。然后,我们可以通过单击附加作业按钮重新附加到同一个作业,当脱离作业时它取代了脱离作业按钮。
通常,在两台机器上同时运行 COMSOL Multiphysics 需要两个许可证,但你可以选中使用批处理许可证选项,以便从远程作业中分离出来,并仅使用一个许可证在本地继续编辑。事实上,你甚至可以向集群提交多个作业并同时运行这些作业,只要这两个作业是同一个模型文件的变体即可;也就是说,它们只是全局参数值不一样。唯一的限制是你的本地用户名需要与远程集群上的用户名相同,这样许可证管理器可以确定同一个人同时使用两个许可证,否则,即使启用了使用批处理许可证选项,也会占用额外的许可证席位。
仿真完成后,系统会提示你打开生成的文件:
集群作业完成后,系统会提示你立即打开已求解的文件。
如果你选择否,稍后仍然可以打开文件,因为该文件已经下载并复制到设置中指定的目录。我们来看一下这些文件:
集群作业期间在本地端创建的文件。
这些文件随着仿真的执行被创建和更新。COMSOL Multiphysics 定期从远程集群中检索每个文件,在进度窗口中更新状态,并在仿真结束后立即通知你。远程端也存在相同的文件:
集群作业期间在远程端创建的文件。注:颜色已从 PuTTY 中的默认配色方案更改为强调 MPH 文件
以下是最相关文件类型的概述:
| 文件 | 远程端 | 本地端 |
|---|---|---|
| backup*.mph | N/A |
|
| *.mph |
|
|
| *.mph.log |
|
|
| *.mph.recovery |
|
|
| *.mph.status |
|
|
| *.mph.host | N/A |
|
使用集群计算功能执行 COMSOL Multiphysics® 仿真
母线板模型非常小,我们不想在集群上实际运行。使用该示例测试功能后,我们可以打开任何模型文件,添加集群计算 节点(使用我们之前设置的默认值),更改节点数量和文件名,然后单击计算。无需再次更改远程运行 选项、调度程序类型和所有相关设置。
当我们在多台主机上运行一个模型时,COMSOL® 软件会执行什么操作?工作如何分配?软件中的大多数算法是并行的,这意味着所有主机上的 COMSOL Multiphysics 进程在同一计算中协同工作。将工作分配在多台计算机上可以提供更多的计算资源,并可以提高针对许多问题的处理能力。
然而,应该注意的是,集群节点之间所需的通信可能会产生性能瓶颈。模型的求解速度在很大程度上取决于模型本身、求解器配置、网络质量以及许多其他因素。你可以在关于混合建模的系列博客中找到更多信息。
使用集群硬件性能的另一个原因是,仿真所需的总内存大致保持不变,但所有主机加起来有更多的内存,因此每台主机所需的内存会减少,这使我们能够运行原本不可能在单台计算机上求解的大型模型。实际上,问题的总内存消耗略有增加,因为 COMSOL Multiphysics 进程需要跟踪它们自身的数据以及它们互相接收的数据(通常要少得多)。此外,进程所需的确切内存量是不可预测的,因此添加更多进程可能会增加单个物理节点耗尽内存并中止仿真的风险。
更简单的情况是运行分布式参数化扫描。我们可以通过使用多个 COMSOL Multiphysics 进程并使每个进程的参数值不同来加快计算速度。我们称这类问题为“高度并行”,因为在求解过程中节点不需要通过网络交换信息。在这种情况下,如果物理节点的数量翻倍,理想情况下仿真时间将减半。实际加速往往没有那么好,因为将模型发送到各个节点需要一些时间,将结果复制回来也需要额外的时间。
为了运行分布式参数化扫描,我们需要激活参数化扫描设置底部的分布式参数化扫描选项。否则,仿真将利用所有集群节点一次运行一个参数,这种情况下,由于在求解器层级执行并行,效率要低得多。
如果运行辅助扫描,你也可以在研究步骤中选中分布参数化求解器 选项,从而在可能的多个物理节点上使用多个进程在多个频率下并行运行频率扫描。请注意,如果你使用连续方法,或者各个仿真相互依赖,那么这种分布参数的方法就不起作用了。
注意:不要在集群计算 节点上使用分布式参数化扫描 选项,因为它的性能已降低。最好在参数化扫描时直接指定。

激活 分布式参数化扫描选项以在不同节点上并行运行每组参数。
为了并行运行扫描,我们还可以使用集群扫描 节点,它将批处理扫描 节点的功能与集群计算 节点远程运行作业的能力结合起来。可以说集群扫描是远程版本的批处理扫描,就像集群计算 节点是远程版本的批处理 节点。我们将在以后的博客文章中更详细地讨论集群扫描。
需要记住的最重要的区别是,集群计算 节点为整个研究提交一个作业(即使它包含扫描),而集群扫描 和批处理扫描 节点为每组参数值创建一个作业。
用 App 进行集群计算
本篇博客文章涵盖的所有内容也可以从 COMSOL Multiphysics 或 COMSOL Server 中运行的仿真 App 中获得。App 只是从其所基于的模型继承集群设置。
从 COMSOL Server 运行 App 时,你可以在 COMSOL Server 的管理网页访问集群首选项。你可以让 App 使用这些首选项为特定的 App 硬连接和定制集群设置。你还可以根据需要将 App 设计成用户可以访问一个或多个低级集群设置。举个例子,你可以在 App 用户界面中设计一个菜单或列表,让用户在不同队列之间进行选择,例如前面提到的“cluster”或“fatnode”选项。
结语
无论你使用的是大学集群、虚拟云环境还是自己的硬件,集群计算 节点都可以让你轻松地远程运行仿真。因此,通常不需要昂贵的装置。事实上,当你在本地处理其他任务时,有时你只需要贝奥武夫集群来运行参数化扫描。
集群计算是一个功能强大的工具,可以帮助你加速仿真、研究详细而真实的设备,最终帮助你实现研究和开发目标。
SLURM 是 SchedMD LLC 公司的注册商标。
Linux 是 Linus Torvalds 在美国和其他国家/地区的注册商标。
Microsoft 和 Windows 是微软公司在美国和/或其他国家/地区的注册商标或商标。
我们以前写过一篇有关 HPC 与 COMSOL Multiphysics® 软件、集群、以及混合计算的博客。但并非所有人的办公室中都有集群可用,或者有可用于构建 Beowulf 集群的硬件,如果我们确实需要集群所能提供的额外计算资源,有哪些可用的选择呢?其中一个解决方案便是云计算,这是一项提供临时性计算能力的服务,可以帮助提升计算能力及生产力。
三种需要更多计算能力的情况
假设您在模拟一个电子器件,希望了解其在运行过程中的温度分布。测试了几种设定之后,您发现您使用的热通量边界条件并非是您模型的最佳近似。要得到更精确的结果,您还需要进行流体流动仿真。但问题是,您基于热通量近似的传热仿真已经几乎占满了您笔记本电脑的全部 4 GB 内存。您需要一个双向耦合,但增加流体流动仿真将会给计算带来更多的自由度,因此需要更多的内存。
现在怎么办呢?您需要更多的计算能力。
换个主题,试想一下您正在为客户进行力学分析,该力学组件中包含许多小细节。为了优化设计,您需要分析大量不同的设计尺寸。但您本地只有一个处理器,每次运行都要花费相当长的时间,您意识到您可能无法在客户的最后期限前完成分析。
解决方案?您需要在多个处理器上并行运行这些仿真。
最后,让我们看一个与涉及的物理场无关,但仍基于这些物理场分析的应用。您已经使用选定的物理场接口建立了模型,但马上要下班了,您希望能尽快、尽量简单地在一夜之间得到模型计算结果。使用直接求解器不需要进行大量的求解器设定及类似工作,但它所需的内存会随您模型的自由度数目的增加而急剧增长。
这次的解决方案呢?您需要一个更大型的电脑。
如果有一个解决方案可以应对所有这三种情况呢…
输入:云计算
这就是我们需要借助云计算的地方。云计算服务是一项能在人们需要时向其提供计算资源的服务。
这一服务有很多优势,特别是在您缺乏时间、资金或经验来投资建立一个传统集群或服务器机柜的情况。您也许并不需要一个 7*24 小时可用的集群,只是在某些时候才需要额外的计算资源,例如,需要更快完成的一次性分析或任务。
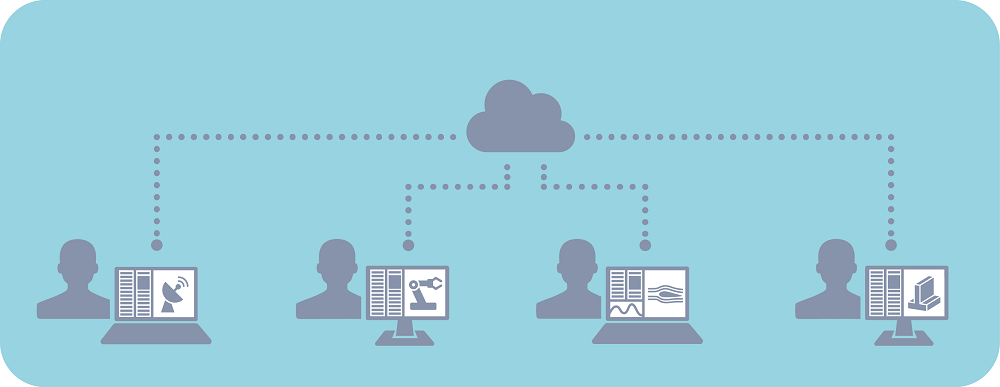
利用 COMSOL Multiphysics® 和云计算的硬件资源,机构可以在需要时使用所需的资源进行不同的分析。
云计算的使用将对您的工作产生积极的影响。能够在需要时增加更多的计算能力,将帮助您更好地完成您日常的 COMSOL Multiphysics® 仿真工作。您不必担心现场缺乏足够的硬件,可以照常进行您的日常操作,同时确定可以在需要时随时利用云进行扩容。
在远程计算资源中使用 COMSOL® 软件
从传统上来看,在使用云计算服务时,您需要拥有所用网络和硬件技术方面的专业知识,还需了解云服务将执行的操作系统及软件,这样才能更好地支持应用程序的运行。在一个典型的操作流程示例中,您需要注册云服务,研究需要的机器规格,租用机器,然后将它连接到您的网络以允许其访问您的许可证服务器。然后就是较容易实现的部分:安装 COMSOL Multiphysics 和运行您的模型。
但由于 HPC 在 CAE 领域中变得越来越重要,于是我们与云计算提供商进行合作,最大限度地降低您进入云计算领域的门槛。
注:COMSOL Multiphysics 长期以来一直支持对远程计算资源的使用,您可以通过用户界面或命令行进行批处理工作,或是使用实时的客户端-服务器技术。要实现这一点,您所需要的仅仅是一个 COMSOL Multiphysics® 的网络浮动许可证 (FNL)。
从以下资源开始:与我们的云计算合作伙伴进行联系
大功率电气设备的一个主要问题是热管理。借助 COMSOL Multiphysics 仿真软件,我们与 BLOCK Transformoren- Elektronik 公司一起开发了一个包含了模拟大功率电气设备的所有重要细节。为了运行此模型,我们必须利用包含混合建模的高性能计算。这篇博客,我们将讨论如何使用 COMSOL 软件完成这个真实的建模任务。
热管理仿真:测试装置
我们的测试装置包括一个周围缠绕着铜线圈的叠片铁芯,一些用于保持稳定性的塑料和铝部件。在距离铁芯 1m 远的地方放置了一个传统的计算机风扇。我们必须计算发生的电磁损耗以及设备周围的湍流非等温流体流动。我们设计的铁芯特意包含了一个气隙,用于分析它对线圈和铝部件内部电流的影响。

电感器装置
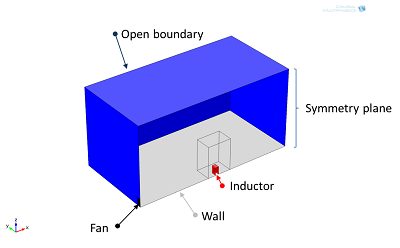
测试装置示意图。
首要工作
工程师,特别是那些有项目期限的工程师一直在寻找计算(和建模)的工作量和准确性之间的合理平衡。因此,最好在建模开始时就考虑对模型进行适当的简化,因为这类模型在几何结构上的长宽比对计算相当具有挑战性。
风扇和设备之间的距离大约是 1m,而铜线圈之间的内部间隙大约是 0.1mm,故长宽比为 10,000。为了使计算时间尽可能短,我们选择了开发子模型的方法,我们建立的第一个模型对压器几何结构进行了简化,用来计算设备周围的大尺度流场。由于模型具有对称性,我们只建立了一半模型的几何结构。我们导出模型的模拟结果,并将其作为下一个计算步骤的入口条件。
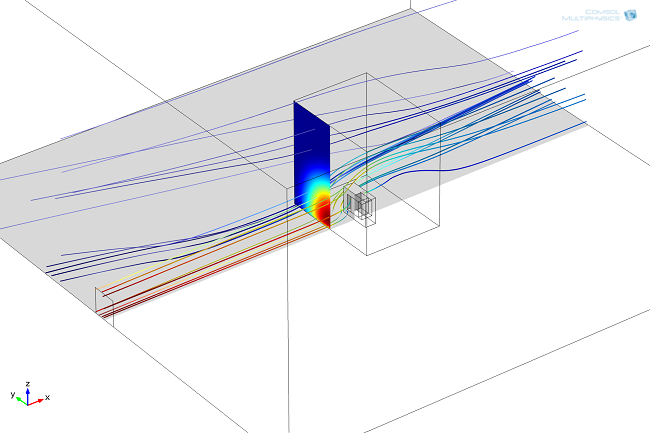
速度场的流线图。速度场被用作详细模型(在切片图的位置)的入口边界条件。
详细的几何结构
电气设备的详细几何结构是在 SolidWorks® 软件中建立的,并通过 CAD 导入模块导入到 COMSOL Multiphysics® 中。我们仅使用了详细子模型的一小部分(约 400mm×900mm)来计算非等温流。电磁部分需要求解的域更小(200mm×200mm)。
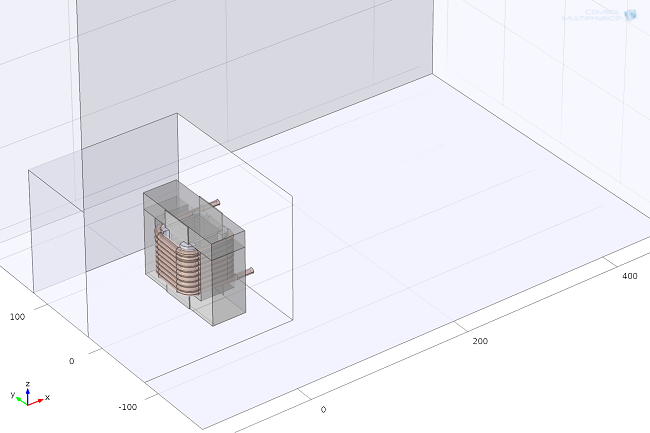
模拟叠片铁芯
采用叠片铁芯是为了减少涡流。我们将使用与 TU Dresden 大学和 ABB 公司相同的方法来定义这个模型。我们将材料均质化,并定义了一个正交各向异性的电导率。这使得我们可以在建模时保证铁芯为单一的整体域,并且避免使用较粗的网格,从而避免了建立每层薄铁芯叠片的几何结构来表征叠层。
电磁损耗
由于施加了 500Hz 的交流电,因此我们必须计算线圈中的电感效应(集肤效应和邻近效应)。此外,铝板和铁芯中的涡流会使设备发热。
")
铝板中涡流的表面图。铁芯中的气隙用红色突出显示。大多数感应电流是在这个间隙附近产生的。
")
铜线圈电流密度的切片图。铁芯中的气隙用红色突出显示。
由于磁滞现象,也存在一些磁化损耗。与涡流损耗相比,磁化损耗相当小,而且没有被明确求解。下表显示了磁化损耗与磁通密度的函数 Qmag = f(B)。我们可以通过求解一个插值函数来表征磁滞损耗,而不是在瞬态研究中计算磁滞。
| 部分 | 电磁损耗 |
|---|---|
| 铜线圈 | 37.2W |
| 铝,涡流 | 36.2W |
| 叠片铁芯,涡流 | 0.02W |
| 叠片铁芯,磁损耗 | 0.004W |
速度场和温度分布
该设备线圈背面的最高温度达到了 125°C。
。")
速度场的流线图和温度分布的表面图。
")
速度场的另一种视图。
多物理场高性能计算的最佳选择
今天,我们的任务是找到变压器热设计的最佳求解方案。在 BLOCK Transformatoren 公司的案例中,他们比较了几种仿真软件的处理方式和结果,最后一致认为 COMSOL Multiphysics 是最适合他们使用的。
最后,这个模型涉及同时求解最多 800 万个自由度,使用了直接和迭代求解器的强大组合。内存的使用最高达到 89GB。
为了能够求解高度复杂的模型,他们选择了具有基准集群的 Ready-to-Go+(RTG+) 软件包,以获得最佳性能。有了 BLOCK 公司为高级仿真的所有设置,我们可以期待他们的产品在未来达到更高的性能极限。
SolidWorks 是 Dassault Systèmes SolidWorks 公司的注册商标。
很多人都需要最新的软件和硬件来提升工作效率,因此,我们要紧跟科技发展的步伐。但如何处理过时的硬件呢?将它们报废或是扔在角落,这都显得有点浪费。其实我们可以利用这些废旧硬件来组建一个贝奥武夫集群,以提升计算速度与生产率。
关于贝奥武夫集群
1994 年, NASA 的一群研究人员利用普通工作站组建了一个小型集群,并将该集群(或称并行工作站)称为贝奥武夫。之后,贝奥武夫集群这个词就被用来描述为使用商品硬件(例如普通工作站)组建、依靠开源软件驱动的集群。这个定义对于计算机硬件和网络互联来说颇为宽泛。最重要的一点是,工作站不再作为工作站使用,而是作为高性能计算机(HPC)集群中的节点。
贝奥武夫集群可用于计算各类问题,但是正如我们之前在混合建模系列博客中提到的,为了更好地利用集群来提升效率,问题必须是可并行的。因此贝奥武夫集群被用于计算粒子模拟、遗传学问题以及一可能对于 COMSOL Multiphysics® 用户来说最为有趣的——参数化扫描和大型矩阵相乘。
但我们为什么会想到使用非 HPC 硬件来组建集群呢?一个可能的原因就是“我们手头已经有硬件了”。例如,在全办公室的工作站或笔记本电脑更新换代之后,我们可能不知道该如何处理过时的旧电脑,但又不想把它们丢掉。一种可行的解决方法就是在办公时间之后或是双休日利用空闲工作站的集中计算资源。
我们需要什么组建集群?
首先,我们需要有硬件可用。在这篇博客中,我们使用了性能可靠的老旧笔记本作为节点,当然也可以使用工作站或旧服务器。通过任意一种方式组建贝奥武夫集群时,我们都应选择具有相似硬件的节点。我们所用的笔记本电脑已不再是“性能优异的怪兽”了,每一台均配备了 Intel® T2400 @1.83GHz 处理器和 2 GB 的 RAM ,并配有以太网网卡,以便连接所有设备。我们还需要一个交换机。在本案例中使用了一个旧的 HP® 1800 交换机,其实也可以使用普通的商品硬件(譬如家庭办公用的五口交换机),这取决于我们需要用到多少节点。

我们的贝奥武夫集群,由六台旧笔记本和一台旧交换机组成。
因为贝奥武夫集群(按照上文中的定义)依靠开源操作系统驱动,我们在笔记本电脑中安装了一个 Linux® 发行版。尽管有专门为贝奥武夫集群计算设计的操作系统,但也可以使用标准的服务器操作系统(例如 Debian® )。
在硬件、网络、操作系统以及共享文件系统设定完成后,最后一步就是安装COMSOL Multiphysics® 软件。无需再安装信息传递接口(MPI)或调度程序, COMSOL 的内置功能已经满足了集群计算的所有需求。
组建贝奥武夫集群及安装 COMSOL Multiphysics
在这次安装中我们选择 Debian® Stable 6 ,这是我在撰写这篇博客时 COMSOL Multiphysics 所支持的一种发行版。接下来需组建系统。在这种情况下,为了使安装工作尽可能地轻松省力,我们只安装基础系统外加一个 SHH 服务器将集群连接至网络。此案例中不需要用到桌面环境,因为它只会降低贝奥武夫系统的性能。
成功安装操作系统后,我们要建立网络以及计算节点的文件共享系统。对于文件共享系统,我们在第一个节点上安装 NFS 服务器作为头节点。然后从这里输出文件共享系统的位置。
以下是一个组建案例:
/srv/data/comsolapp 用于 COMSOL App /srv/data/comsoljobs 用于 为用户存储 COMSOL 的集群工作 在计算节点上,我们将自动挂载这些共享内容。
因为系统中没有安装桌面环境,我们需使用自动安装程序(见 COMSOL Multiphysics 安装指南第 77 页)。使用安装媒介中的 ‘setupconfig.ini’ 文件并按需要对其进行编辑。
最重要的一步是将 ‘showgui’ 选项从 ‘1’ 设置为 ‘0’ 。另一个要点是目标路径。这里我们选择网络共享,因为比较容易维护和升级到最新版本的 COMSOL Multiphysics 。
增加参数 ‘-s /path/to/the/setupconfig.ini’ 以开始安装,例如:
cd /media/cdrom/ ./setup –s /path/to/the/setupconfig.ini
现在基于文本的安装程序启动并将输出结果发送给终端。
为了告知 COMSOL Multiphysics 哪些节点可用,我们需建立一个简单的包含主机名列表的 ‘mpd.hosts’ 文件:
mpd.hosts cn01 cn02 ... cn06 最后,我们在第一个节点以及其他六个节点上启动 COMSOL 服务器:
//comsol server -f mpd.hosts -nn 6 -multi on 现在您可以在桌面上启动 COMSOL Multiphysics 并连接到服务器了。
结论:旧硬件提升生产率
我们在案例集锦中选择了修改后的音叉模型来测试 ‘崭新的’ 集群。在测试中,我们决定将参数化扫描中计算的参数数量增加至 48 。接下来用 COMSOL Multiphysics 的批命令在 1 至 6 台笔记本中计算模型。下图中展示了每一天测量出的总模拟量。

生产效率增长(工作量/天),包含了使用不同数量的笔记本从打开文件到存储结果的总时间。
正如我们看到的,如果使用 6 台笔记本,那么几乎可以达到每天 140 的工作量,相比之下,一台笔记本每天的工作量不到 40 。总体来说增速接近 3.5 倍。考虑到我们使用的是旧的笔记本电脑,效率的提升非常明显。
需要注意的是,测量时间并不是求解时间,而是总模拟时间。这包括打开、计算和保存模型。打开和保存是自然连续的,根据阿姆达尔定律(在之前关于“批扫描”博客中有提及),我们是看不到求解器提速的。如果我们能够将贝奥武夫集群与 COMSOL Client/Server 功能相关联并比较计算时间,我们将能得到更为显著的生产率提升。
总的来说,这意味着我们完全可以使用旧的硬件与 COMSOL Multiphysics 来提高生产率以及加快计算速度(尤其是参数计算)。
Debian 是美国 Software in the Public Interest, Inc. 公司的注册商标。
HP 是 Hewlett-Packard Development Company, L.P. 公司的注册商标。
Intel 是 Intel 公司在美国及/或其他国家的商标。
Linux 是 Linus Torvalds 的注册商标。
如今新产品的研发周期越来越短,为了在市场竞争中抢占先机,研发工程师和科学家们需要一件高效的工具,来帮助他们最快地获取计算结果,并摆脱重复性的例行工作。COMSOL Multiphysics® 正是他们需要的!COMSOL 软件拥有参数化扫描等多种内置功能,可帮助用户提高仿真工作效率。除了能够实现图形建模之外,它还拥有应用编程接口(Application Programming Interface,简称 API)。借助 API,用户便能对任意重复的建模步骤实现自动化操作。下面我们来了解一下适用于 Java® 的 COMSOL API 接口。
COMSOL API 简介
COMSOL API 是一个软件接口,它包含了所有用于定义 COMSOL 模型的算法和数据结构。您每一次在 COMSOL Desktop® 上建立模型,其实就是在同后台的 COMSOL API 进行交互。之前的一篇博客文章专门探讨了 LiveLink for MATLAB®,该接口在运行时也使用了 COMSOL API,只不过实现途径是交互式而非编译式。我们今天将专门讨论 COMSOL API for use with Java®。
作为代码生成器的 COMSOL Desktop
即使您并非专业级的 Java® 编程师,也能轻松使用 COMSOL API。您可以直接从手头的 COMSOL Desktop 工具开始操作。在这一图形建模环境中执行的所有动作都会记录在模型操作历史中。之后您还可以将操作历史导出为 Java 代码,操作方式是在保存模型时将文件类型设为“Java® 模型文件”。这种方法对于您构建程序的基本模块是十分有用的。
Hello World!
为了让大家逐步熟悉操作流程,我们从一个简单而著名的程序入手,它就是 COMSOL API 版本的“Hello, World!”程序。
首先在 COMSOL Desktop 中创建一个全部由三维几何构成的模型,接着在几何中添加一个 0.1 米 × 0.2 米 × 0.5 米的长方体,然后将其保存为“Java® 模型文件”,名称改为“HelloWorld.java”。
此时在文本编辑器中打开输出,所得代码如下:
import com.comsol.model.*; import com.comsol.model.util.*; public class HelloWorld { public static void main(String[] args) { run(); } public static Model run() { Model model = ModelUtil.create("Model"); model.modelNode().create("comp1"); model.geom().create("geom1", 3); model.geom("geom1").feature().create("blk1", "Block"); model.geom("geom1").feature("blk1").set("size", new String[]{"0.1", "0.2", "0.5"}); model.geom("geom1").run("fin"); return model; } } 前两行代码为指向 COMSOL API 的 import 语句,紧接着是 HelloWorld 的类名定义。按照 JAVA 的编程规范,类名应该和文件名保持一致。
这个类中包含了一个 main() 方法,该方法会转而调用静态的 run() 方法,由此创建并返回 Model 对象。在小型的编程项目中,您可以直接对该方法进行修改,换言之,未必定要使用 Java 语言中面向对象的高级特征。
压缩历史记录功能
COMSOL Desktop 中还有一个可与代码生成配合使用的实用功能,那就是“文件”菜单中的“压缩历史记录”。在建立模型时,我们经常需要在后续步骤中删除或者来回移动之前添加的一些特征。这些更改操作都会记录到模型历史中,因此存留了大量多余的步骤。
“压缩历史记录”功能可以清除历史记录,移除重复与删除的条目,根据“模型开发器”的顺序重新调整全部记录。若在导出之前启用此功能,您就能够得到整洁的代码。
那么为什么不在保存 Java® 文件之前自动清除历史记录呢?这是因为有时候历史记录可能是有用的。
假设您正在使用 COMSOL API 开发代码,但突然发现其中一部分代码可以通过 COMSOL Desktop 进行快速创建。于是您便不得不开始修改手中的模型,然后将其保存为 Java 文件。幸运的是,您没有在保存代码之前压缩模型历史,因此顺利地在导出代码的末尾找到了所有更改记录。相比于在完整的模型代码中搜寻分布零散的更改操作,这种方法省去了大量麻烦。
编译并运行 COMSOL API 代码
Java® 是编译型语言,这意味所有想要实现的功能都必须在类文件中编写对应的代码。为此您需要一个 Java 编译器,例如甲骨文推出的免费 Java® 开发工具包(JDK)。
安装好 JDK 后,便可以使用
comsolcompile(Linux® 或 Mac® 系统中的comsol compile)
命令,该命令是 COMSOL 软件中的一部分,主要用于编译代码,它能够自动为 Java® 编译器建立通向 COMSOL API 的环境变量。
在编译上文中的示例时,您要用到下方命令
comsolcompile -jdkroot PATH_TO_JDK HelloWorld.java
其中 PATH_TO_JDK 指的是 JDK 的安装目录。需要注意的是,COMSOL API 是基于 Java® 1.5 版本,且上述方法适用于 JDK 1.5 或 1.6 版本。
您还可以使用诸如 Eclipse 的集成开发环境(Integrated Development Environment,简称 IDE)。使用 Java 1.5 兼容包创建自己的项目,然后将 COMSOL Multiphysics® 安装目录下“plugins”子目录中的所有 JAR 文件添加至构建路径。
将代码编译成了类文件后,您就可以通过“文件 > 打开”菜单在 COMSOL Desktop 中打开它。如果要对上文的示例进行类似处理,您将会看到带有一个长方体的 Hello World三维几何模型。常规的 COMSOL mph 模型文件也能够取得相同的效果。下一步,我们要做些改变,尝试操作一些普通的模型文件无法胜任的高级功能。
不过,先别急着去修改示例。在这之前,让我们仔细研究一遍上文中 run() 方法代码的结构和含义。
简要介绍 COMSOL API
通过“Hello World”示例,我们学会了如何使用 COMSOL API 的核心功能。接下来我们来仔细查看一遍 run() 方法,了解它是如何一步步实现相关功能的。
第一行代码,
Model model = ModelUtil.create("Model");
使用 ModelUtil.create() 创建一个新模型,这一静态方法取名称(字符串 Model)作为变元。 ModelUtil 是一系列实用工具方法的集合,也是 COMSOL API 的小帮手。借助它,您可以加载模型,从零创建新模型,或实现其他各种操作。
ModelUtil.create()
返回了一个 Model 对象。此对象包含了 COMSOL 模型的所有设置,也就是说它涵盖了您通常在 COMSOL Desktop 的“模型开发器”中看到的完整模型树。
下一行代码
model.modelNode().create("comp1");
在模型树中创建了一个新的组件节点。随后,下一行代码中添加了模型组件的关联几何
model.geom().create;("geom1", 3);
第二个变元(数字 3)将组件几何扩展为三维结构。
这里需要注意的是,两个 create() 方法中的第一个变元都是一个“字符串”,即所谓的标记。由于模型内很可能包含许多类型相同的特征,因此为了唯一识别这些特征,我们必须在 model 对象中每一处都使用标记。举例来说,模型中可能存在多个组件,每一个组件对应不同的几何,而且组件几何可能包含了许多类型相同的基本形状,因此物理场设置可能使用了大量类型相同的边界条件。综上所述,为每个项分配一个独一无二的标记是使代码保持清晰整洁的好方法。
只要在“主屏幕”选项卡下的“模型开发器节点标签”菜单中启用“显示名称和标记”或者“显示类型和标记”设置,就可以将任何 COMSOL Multiphysics 模型标记显示在 COMSOL Desktop 中。
在“模型开发器节点标签”设置中启用“显示名称和标记”或“显示类型和标记”选项后,标记就会显示在 COMSOL Desktop “模型开发器”中。
下一行代码,
model.geom("geom1").feature().create("blk1", "Block");;
为第一个几何结构 "geom1" 创建了一个长方体。
您可以清晰地辨认出这一行代码在模型树中的层次。前半段代码 model.geom("geom1") 的操作是将命令和几何结构 "geom1" 关联起来,后半段代码 feature().create("blk1", "Block") 向几何结构添加了一个新特征。这个新特征是一个被标记为 "blk1" 的长方体。想象着您正在操作 COMSOL Desktop,前半段代码表示右键单击 "geom1",后半段表示在弹出的几何菜单中选择“长方体”。
当长方体创建完成后,可通过下一行代码修改它的属性
model.geom("geom1").feature("blk1").set("size", new String[]{"0.1", "0.2", "0.5"});
同样地,前半段代码指定了 "geom1" 的第一个长方体 "blk1",后半段使用 set() 方法修改了长方体的尺寸属性。
后半段代码的第一个变元指定了您想要修改的属性,在本示例是“尺寸”。第二个变元赋予了尺寸属性三个新数值,分别表示长方体的宽、高和长。
请注意,尽管这些属性被设置成了实数,但变元却是以字符数组的形式传递的。这是为什么呢?要记得,您可以在 COMSOL 软件的任意位置输入数学表达式来替代具体数值。就这一点而言,COMSOL API 也不例外,因此这类属性是以字符串的形式传递的。
现在,运行模型返回前的最后一行代码
model.geom("geom1").run("fin");
即可返回新模型。最后一行代码旨在使几何结构成型,这相当于在 COMSOL Desktop 中按下了“全部构建”按钮。
以上就是 COMSOL API 的简要介绍,您需要的全部相关信息都包含在其中。当然,实际操作会涉及到更多具体细节,借助 COMSOL Desktop 生成的参考代码和 COMSOL API for use with Java® 的参考文档,您便可以掌握所有的细节。
应用案例:创建螺线管电感器的几何结构
为了更具体地演示 COMSOL API 的实际应用,让我们来看看“案例下载”中的螺线管电感器模型。
该模型旨在对特定线圈设计的自感现象进行仿真。仔细观察其几何结构,您会发现它是由一个个长方体搭建起来的。模型中螺线管的尺寸是固定值。设计这一类装置时,我们必须尝试不同的配置,比如多次修改电感器的横截面和线圈匝数等。为实现这一目的,您可以在 COMSOL Desktop 中建立参数化几何。
对横截面进行参数化是一个简单的操作,但是另一方面,由于每三匝导线之间的长度互不相同,因此绕组数目无法在 COMSOL Desktop 中用参数来表示。不过正如上文所述,借助 COMSOL API 就能指定 Java® 项目中长方体的所有参数。您可以利用这一点来自动创建螺线管电感器的几何结构。
在上面的“Hello World”示例中,我们学会了如何创建长方体;为了建立螺线管电感器的几何模型,我们需要创建许多尺寸属性不同、方向相异的长方体,并将它们合理地布置在理想结构中。在编写代码时,您需要追踪下列变量:
| 变量代码 |
|---|
横截面( wire_width and wire_height) |
一段导线长度(piece_length) |
位置(pos_x and pos_y) |
方向(rotation_angle) |
导线间距(inner_spacing and loop_spacing) |
匝数(n_loop) |
接着生成长方体,使之构成循环的螺线管。
毫无疑问,我们需要为每一个长方体指定一个独特的标记。一种方法是通过将长方体的计数器与 "blk" 一类的基础字符串相关联,然后手动创建。不过,您有更好的选择——COMSOL API 提供的 uniquetag() 方法。此方法不仅能实现同样的效果,还能在内部追踪计数器,保证同一个标记不会使用两次。
下方动画中的每一个长方体标记都是通过如下代码生成的
model.geom("geom1").feature().uniquetag("blk")
借助独一无二的新标记,您便可以创建长方体并设置相关属性了。除了 "size",您还需要更改 "pos" 和 "rot" 属性,它们分别用于控制位置和方向。完成设置后,即可更新变量,进入下一次迭代了!
使用 COMSOL API for use with Java® 自动生成螺线管电感器的几何结构。
还能做什么?
除了创建几何结构,COMSOL API 还能完成非常多的操作。事实表明,COMSOL Desktop 能够实现任何常规建模任务的自动化操作。比如在螺线管电感器示例中,可以自动计算出模型更新后的新结果。您还可以在代码中运行参数化扫描,借此对整个螺线管电感器的参数范围进行全面的计算。然后便可以通过创建绘图将计算结果保存为图像文件,并将全部数值保存到文件中。
实际上,本篇博客文章仅仅介绍了 COMSOL API 的基础应用。除了在 COMSOL Desktop 中执行手动编程任务外,COMSOL API 还能让您访问并控制有限元网格、有限元矩阵和求解结果的数据集这一类的数据结构。
COMSOL API 工具不仅可用于编写能在 COMSOL Desktop 中打开的类文件,还能编写出与 COMSOL Server 进程相连接的程序,甚至还能编写集成了 COMSOL 技术的独立程序。总而言之,若您需要长期执行同一个仿真任务,强大灵活的 COMSOL API 工具就能够将让此任务自动进行。
Eclipse 是 Eclipse 基金会的商标。Linux 是 Linux Torvalds 的商标。Mac 是注册在美国和其他国家/地区的苹果公司的商标。MATLAB 是 MathWorks 公司的注册商标。Oracle 和 Java 是甲骨文公司和/或其子公司的注册商标。
到目前为止,我们在混合建模系列博客中还没有详细讨论的一件事是,当向我们的计算中增加更多计算资源时,我们可以期待怎样程度的加速。今天,我们考虑一些解释并行计算局限性的理论研究,并将介绍如何使用 COMSOL 软件的批处理扫描 选项。这是一个内置的、易并行计算功能,可在达到极限时提高性能。
Amdahl 定律和 Gustafson-Barsis 定律
我们之前已经提到过的如何通过增加计算单元来提高速度是基于算法的(在这篇文章中我们将使用术语进程,但添加的计算单元也可以是线程 )。一个严格的串行算法,像计算Fibonacci 数列的元素,完全不能从增加过程中受益,而并行算法,如向量加法,可以利用与向量中的元素一样多的处理器。实际中的大多数算法都介于这两者之间。
为了分析一个算法可能的最大加速,我们将假设它由一小部分完全并行化的代码和一小部分严格串行化的代码组成。我们调用并行代码  的分数,其中, 是介于(包括) 0 和 1 之间的一个数字。这自动意味着我们的算法有一个等于
的分数,其中, 是介于(包括) 0 和 1 之间的一个数字。这自动意味着我们的算法有一个等于  的串行代码片段。
的串行代码片段。
考虑 P 个活动进程的计算时间 T(P),从 P=1 开始,我们可以使用表达式  。当运行 P 个进程时,代码的串行部分不受影响,但完全并行化的代码的计算速度将提高P倍。因此,P 进程的计算时间为
。当运行 P 个进程时,代码的串行部分不受影响,但完全并行化的代码的计算速度将提高P倍。因此,P 进程的计算时间为  ,加速度为
,加速度为  。
。
Amdahl 定律
这个表达式是Amdahl 定律的核心。对于不同的值 和  绘制图
绘制图  ,我们现在在下图中看到一些有趣的东西。
,我们现在在下图中看到一些有趣的东西。
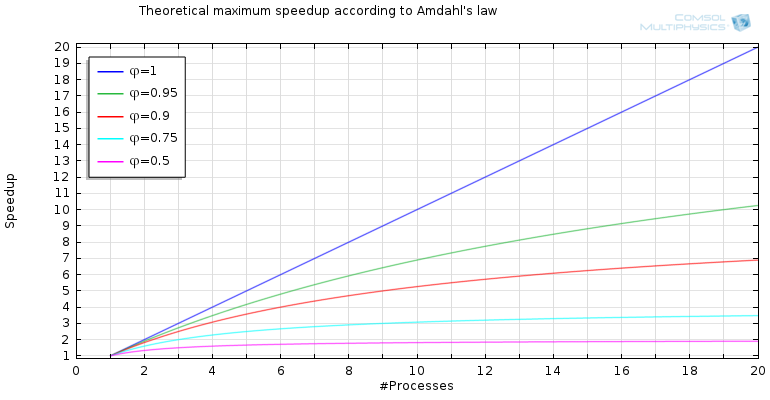
为可并行化代码的不同部分增加进程数的加速比。
对于 100% 并行化代码,极限是不存在的。然而,我们发现对于  ,渐近极限或理论最大加速比为
,渐近极限或理论最大加速比为  。
。
对于 95% 并行化的代码,我们发现  ,即使我们有无限数量的进程,最大加速也是 20 倍。此外,我们有
,即使我们有无限数量的进程,最大加速也是 20 倍。此外,我们有  ,
,  和
和  。当减少并行化代码的比例时,理论最大加速比会迅速下降。
。当减少并行化代码的比例时,理论最大加速比会迅速下降。
但不要现在就放弃回家!
Gustafson-Barsis 定律
Amdahl 定律没有 考虑到一件事,那就是当我们购买一台速度更快、内存更大的计算机来运行更多进程时,通常不是想更快地计算之前的小模型。相反,我们想要计算新的、更大(更酷)的模型。这就是 Gustafson-Barsis 定律的全部内容。它基于这样一个假设,即我们要计算的问题的规模随着可用进程的数量线性增加。
Amdahl 定律假定问题的大小是固定的。当添加新的处理器时,它们处理的是最初由较少数量的进程处理的部分问题。通过添加越来越多的进程,我们并没有充分利用所添加进程的全部能力,因为最终它们能够处理的问题大小达到了下限。然而,假设问题的大小随着添加的进程数量的增加而增加,那么我们就将所有进程利用到假设的水平,并且执行计算的加速是无限的。
描述这种现象的方程是  ,这为我们提供了一个更为乐观的结果,即所谓的缩放加速(类似于生产力),如下图所示:
,这为我们提供了一个更为乐观的结果,即所谓的缩放加速(类似于生产力),如下图所示:
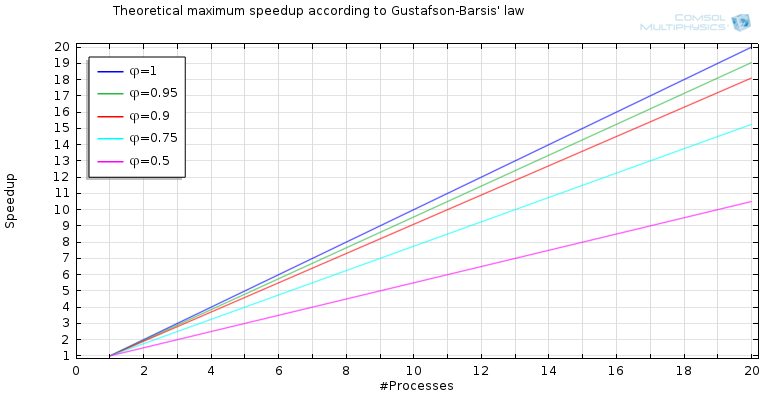
当考虑到工作的规模通常会随着可用进程的数量而增加时,我们的预测就更加乐观了。
通信成本
Gustafson-Barsis 定律意味着,我们拥有的能添加到进程中的资源才能限制我们可以计算的问题的大小。然而,还有其他因素会影响加速。到目前为止,我们在这个系列博客中试图强调的一点是,通信成本较高。但是我们还没有谈到它有多贵,所以让我们看一些例子。
让我们考虑在并行进程中由所需的通信和同步所主导的系统开销,并将其描述为计算时间的增加。这意味着当我们增加进程数量时,通信量也会增加,而这种增加将被函数  所描述,其中
所描述,其中  是一个常数,
是一个常数, 是某个函数。因此,我们可以通过以下方式来计算加速比:
是某个函数。因此,我们可以通过以下方式来计算加速比: 。
。
下面的图显示了并行化代码的比例为 95% 的情况,我们可以看到对于不同的 函数,加速比随着进程数量增加的情况,假设 c=0.005(这个常数在不同的问题和平台之间会有所不同)。在没有系统开销的情况下,结果正如 Amdahl 定律所预测的那样,但是当我们开始增加系统开销的时候,我们看到一些事情正在发生。
对于线性增加的系统开销,我们发现在通信开始抵消更多进程增加的计算能力之前,加速比不会大于 5。对于二次函数,,结果甚至更糟,您可能还记得我们之前关于分布式内存计算的博客文章,在多对多通信的情况下,通信的增加是二次的。
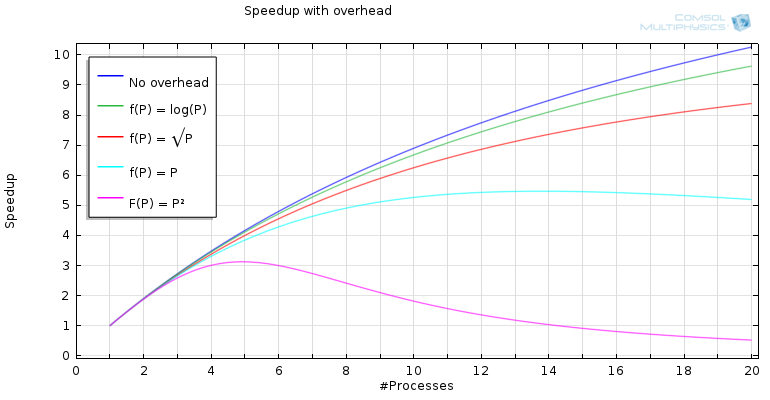
增加系统开销的加速比。常数 c 被选为 0.005。
由于这种现象,当添加越来越多的进程时,我们不能期望在集群上有加速,例如,一个小的瞬态问题。通信量的增加将比增加进程带来的任何增益都快。然而,在这种情况下,我们只考虑了一个固定的问题大小,随着我们增加问题的规模,通过通信引入的“减速”效应将变得不那么重要。
COMSOL Multiphysics 中的批处理扫描
现在让我们离开理论,学习如何使用 COMSOL Multiphysics 中的批处理扫描功能。作为我们的示例模型,我们将使用 COMSOL 模型库中提供的无极灯。该模型很小,大约有 80,000 个自由度,但在其解中需要大约 130 个时间步长。为了使这个瞬态模型参数化,我们将计算不同功率的灯模型,即 50W、60W、70W 和 80W。
在我的工作站,一台配备 Intel®Xeon®E5-2643 四核处理器和 16GB RAM 的富士通 ®CELSIUS® 上,得到了以下计算时间:
| 内核数量 | 每个参数计算时间 | 扫描计算时间 |
|---|---|---|
| 1 | 30 分钟 | 120 分钟 |
| 2 | 21 分钟 | 82 分钟 |
| 3 | 17 分钟 | 68 分钟 |
| 4 | 18 分钟 | 72 分钟 |
这里的加速远非完美——三核仅为 1.7 左右,四核甚至有所降低。这是因为它是一个小模型,每个时间步内每个线程的自由度数较低。
现在,我们将使用批处理扫描功能以另一种方式并行化这个问题:我们将从数据并行 切换到任务并行。我们将为每个参数值创建一个批处理作业,看看这对我们的计算时间有什么影响。为此,我们首先激活“高级研究选项”,然后右键单击“研究1”并选择“批处理扫描”,如下面的动画所示:
如何在模型中激活批处理扫描,包括参数值,并指定同时作业的数量。
下图显示了通过控制并行化可以获得的生产率或“加速比”。当使用4个内核运行一个批处理作业时,我们从上面得到的结果是:72 分钟。当将配置同时更改为两个批处理作业时,每个批处理作业使用 2 个核,我们可以在 48 分钟内计算所有参数。最后,当同时计算4个批处理作业时,每个批处理作业使用一个处理器,总计算时间为 34 分钟。这使速度分别提高了 2.5 倍和 3.5 倍——比单独使用纯共享内存进行并行化要好得多。
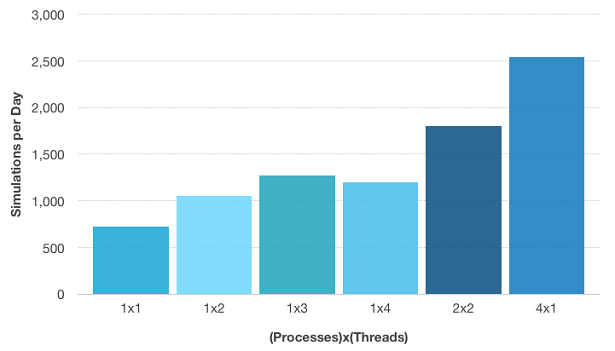
无极灯模型的每天模拟。“4×1”表示 4 个批处理作业同时运行,每个作业使用一个内核。
混合建模系列博客结语
在这个系列博客中,我们了解了共享、分布式和混合内存计算,以及它们的优缺点,以及并行计算的巨大潜力。我们还了解到,在计算领域,没有免费的午餐。我们不能只是添加流程,并希望为所有类型的问题提供完美的加速。
相反,我们需要选择最好的方法来并行化一个问题,以便从硬件中获得最大的性能增益,这就像在解决一个数值问题时,我们必须选择正确的求解器来获得最佳求解时间。
选择正确的并行配置并不总是容易的,而且很难事先知道应该如何“混合”并行计算。但在许多其他情况下,经验来自反复琢磨和测试,然而使用 COMSOL Multiphysics,我们就有可能做到这一点。用不同的配置和不同的模型自己尝试一下,很快您就会知道如何设置软件以获得硬件的最佳性能。
Fujitsu 是 Fujitsu Limited 在美国和其他国家/地区的注册商标。CELSIUS 是 Fujitsu Technology Solutions 在美国和其他国家/地区的注册商标。Intel 和 Xeon 是 Intel 公司在美国和/或其他国家/地区的商标。