

在讨论了关于冰川流动模型之后,我们将深入研究地球物理建模的一个重要组成部分:使用观测值修正数值模型的参数。今天,让我们看看如何使用 COMSOL Multiphysics 软件和优化产品,通过间接观察来量化参数的敏感性和推断未知参数。
耦合模型和数据
模型总是需要输入已知的参数,有时甚至需要很多。虽然这些参数中的一些是众所周知并且容易找到的(例如,水的密度或理想气体常数),但由于各种原因,经常有一些参数是未知的。例如,在冰川学中,一个难题是冰通常很难收集(如高海拔和极端纬度),温度和天气条件使野外工作极具挑战性。此外,极地冰盖和高山冰川的覆盖面非常广阔。
在这些情况下我们可以使用间接观察和建模的方法来推断想要找到的参数。在冰川学中,受益于卫星和雷达干涉测量(InSAR),我们得到了大量的表面形貌和表面速度数据。相反,基底滑度和基岩地形很难获得和测量。
在这种情况下,优化提供了直接观察系统状态来推断输入参数值的能力。这被叫做逆向建模,因为我们从对解(输出)的观察中推导出输入参数的值。为此,我们最小化一个名为目标或者成本的函数,它量化计算当前解与观测值的差距。假设一个解u和对这个解的观察u_{obs},成本函数j可以写为j=\|u-u_{obs}\|,因此,我们调整未知(或不太了解)的参数,以便u越来越接近u_{obs}即j变小。
执行逆建模的经典方法是通过试错法,但是对于向量值参数,这可能会变得非常繁琐。更系统的方法是计算成本函数的梯度j并使用该信息来确定参数的每个值应该增加还是减少。这就是所谓的基于梯度的优化。
使用 COMSOL Multiphysics®计算梯度
考虑一个问题M,其中包含一组m参数\alpha,它的解n是维向量u,例如M(u(\alpha))=0。首先,我们定义一个成本函数j(u(\alpha)),对于每个参数\alpha_k, 1\leq k \leq m,我们希望通过找到\partial j/\partial \alpha_k。链式法则告诉我们:
成本函数是显式已知的,但我们仍然需要计算\frac{\partial u}{\partial \alpha_k}。同样,使用链式法则,我们得到:
其中,n×n 阶矩阵\frac{\partial M}{\partial u}是问题的雅可比矩阵。
此时,直接的解决办法是求解m参数的 n×n 阶线性系统。然而,这种求解方法计算量很大,因为m计算所有离散化的控制变量。例如,一个全局标量控制变量需要一个解,一个空间分布的控制变量至少需要含N个网格单元的个解(假设它是以 0 阶离散的,这是元素常数)。
首选的解是伴随矩阵方法,这是 COMSOL 软件中的默认方法。改写前面的公式,我们发现:
我们来介绍一下伴随解向量u^*,定义如下:
从右边乘以系统雅可比行列式\frac{\partial M}{\partial u},并转置为一个 n×n 阶的线性系统:
一旦这个系统被求解后,u^*众所周知,m梯度的分量减少到m矩阵向量乘积。
这种方法基于对偶理论和最优控制,很难在无限维中导出。详细信息可以查阅J.L. Lions, Optimal Control of Systems Governed by Partial Differential Equations, Springer-Verlag, 1971.
基于梯度优化的冰川分析
这里讨论的 2D 模型可以看作是实际冰川的中心流线,但是结果可以扩展到 3D。几何形状的灵感来自瑞士阿尔卑斯山Haut glacier d’Arolla 山脉,它长 5 公里,厚达 200 米,平均坡度为 15%。
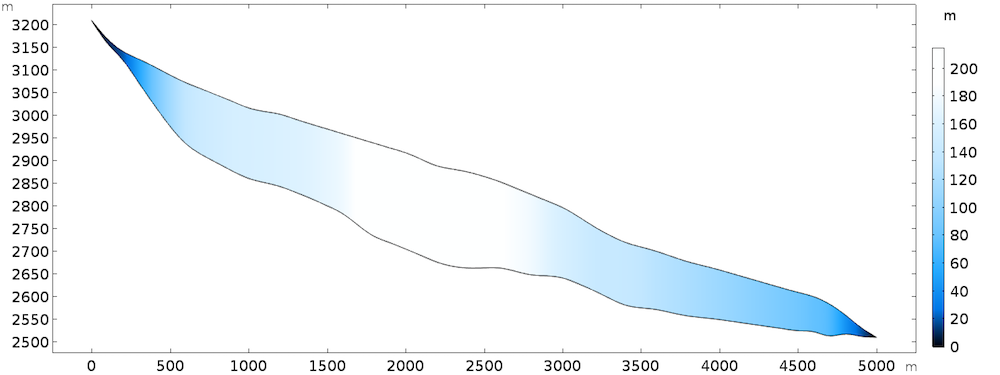
模型几何形状,按厚度着色。
边界条件包括下边界的基底滑移和表面的开放边界。流体的本构方程是具有温度依赖性的非牛顿幂律。底部滑动由具有变化滑移长度的黏性 Navier 滑动给出:
\begin{cases}
20m \mbox{ if } 0\leq x \leq 1000 \\
50m \mbox{ if } 1000\leq x \leq 4000 \\
200m \mbox{ if } 4000\leq x \leq 5000
\end{cases}
我们施加这种变化的滑移长度,目的是使其在尝试从观察中根据观测值推断时更具挑战性。所有详细信息都可以在上一篇关于冰流建模的博文中找到。表面温度为 -20 ℃,底部温度为 -5 ℃。
稳态解返回以下速度场:
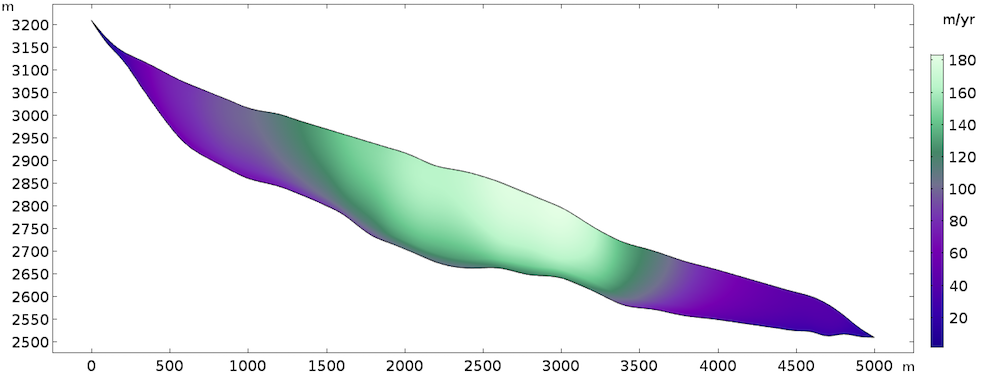
计算的速度场。
在没有数据的情况下构建测试和示例的经典方法是平行实验方法。您只需用一组给定的参数求解一个问题,并提取将作为数据的解值。我们可以改变参数的值,并进行数据同化,以推断用于生成数据的原始值。为了实现一个真实的平行实验,向从数值解中提取的数据添加一些高斯(白色)噪声是很重要的。如果没有,我们将会犯下因果倒置的错误。
执行灵敏度分析
逆向分析的第一阶段是敏感性。对于这一步,我们假设几何形状是准确已知的,并侧重于表面速度数据。为了生成我们的数据,我们只需使用结果部分的导出节点,就可以在受限于表面的数据子集上导出切向速度,并添加一些均匀的噪声(使用预定义的随机函数)。这里,我们添加 10% 的噪声,模拟典型的测量误差。

左侧:数据导出节点。右:原始表面速度和生成的数据。
让我们计算模型对几个控制变量的灵敏度(梯度)。由于计算梯度的成本与控制变量的数量无关,所以我们计算关于滑移长度L_s的梯度(定义在底部边界上),黏度\mu,整体定义的密度\rho。
接下来,我们添加一个灵敏度节点并根据需要定义尽可能多的控制变量字段。对于每个控制变量字段,定义控制变量名,初始值(对梯度而言,它是线性化的关键)和离散方法。在本例中,我们用不连续的常数拉格朗日函数离散每个控制变量,使得沿单元或边的变量是常数,从而使模拟求解更快并且更容易缩放。

滑移长度的控制变量字段的定义说明。
为了便于将其考虑在内,在灵敏度接口定义的控件变量名必须是物理设置中使用的名称。
然后,我们需要根据我们的表面速度观测定义成本函数。使用经典最小二乘法可以将成本函数定义为表面\Gamma_s上计算的和观测的切向表面速度之间的差异的模数L^2:
其中,u_{obs}是使用导出数据文件的插值函数定义的。
在灵敏度接口使用积分目标节点定义成本函数。在当前情况下,在表面\Gamma_s上选择积分。

最后,我们添加一个灵敏度研究步骤,它允许我们从在灵敏度节点定义中选择一个或多个成本函数以及控制变量。研究还定义了梯度法(默认情况下为伴随矩阵)。
在这种情况下,我们不需要修改灵敏度研究步骤,因为已经在敏感性节点设置好了。我们可以简单地运行研究。
该研究计算了灵敏度节点中给定的控制变量值的解作为初始值(与生成数据的“真实”值不同)。然后,将直接问题的雅可比矩阵转置求解伴随问题,最终计算灵敏度。
回想一下,灵敏度是成本函数相对于控制变量的梯度,它们与相应的变量具有相同的维数。离散化的一个主要结果是,对于向量值控制变量(即除了全局标量变量之外的任何控制变量),梯度的每个分量由网格单元的局部大小来缩放。这在优化中是正常的,但会妨碍在各向异性网格上生成可读取的灵敏度图。特别地,使用恒定不连续形状函数离散化的控制变量需要由网格边缘长度归一化h_k在其上定义它们(即,在主体中定义的控制变量的元素的面积或者在边界上定义的控制变量的边的长度)。
还要注意,梯度值取决于原始参数和成本函数的绝对值。要比较这两个值,需要对它们进行缩放。对于控制变量组件\alpha_k和灵敏度\widetilde{\alpha_k}=\partial j/\partial \alpha_k,缩放和网格标准化的灵敏度\widetilde{\alpha_k}^*可以写作:
其中,直接由变量dvol给出的单元大小,是作为初始值给定的控制变量值,并且j(\alpha_0)是成本函数的实际值(通常由变量opt.iobj1给出)。取绝对值是因为梯度的符号与灵敏度评估并不真正相关。
话虽如此,我们现在可以看看缩放后的灵敏度。首先是黏度和密度的灵敏度。
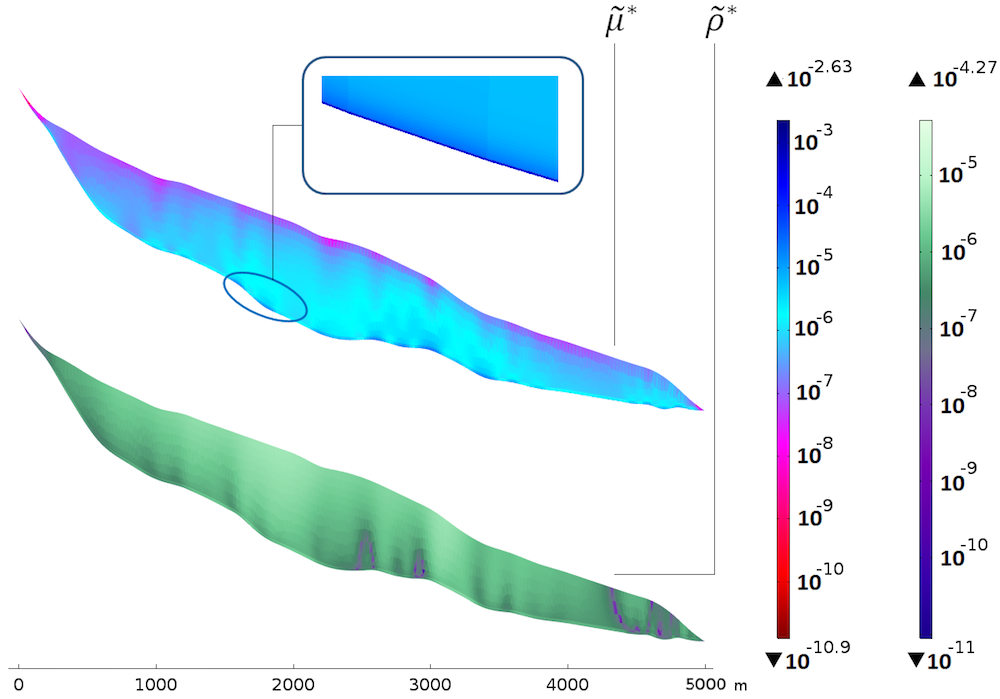
黏度(顶部)和密度(底部)的灵敏度。颜色表需取对数。
绘图\widetilde{\rho}^*的底部表明灵敏度随厚度相当均匀,但接近表面时稍高。厚度的均匀分布似乎是自然的,因为密度主要通过静水压力以重力的形式出现,静水压力与深度成线性关系。基岩中的坡度变化与更高灵敏度的“柱”之间存在相关性。接近表面的灵敏度较高可能是因为表面速度:接近数据点时,与真实密度的偏差更明显。
绘图\widetilde{\mu}^*的最高处展示了一幅截然不同的画面。灵敏度随深度明显增加,沿基岩出现一层灵敏度非常高的薄层。这可以用滑动边界条件对黏度的依赖性来解释。对于比较值,最大值\widetilde{\mu}^*为大约是\widetilde{\rho}^*的 50 倍,因此,与密度相比,该模型显然对黏度的扰动更为敏感。
仔细观察下图中的基岩灵敏度,该图显示了相对于滑移长度\widetilde{L_s}^*的比例灵敏度。作为比较,我们还绘制沿岩床的绘图\widetilde{\mu}^*。
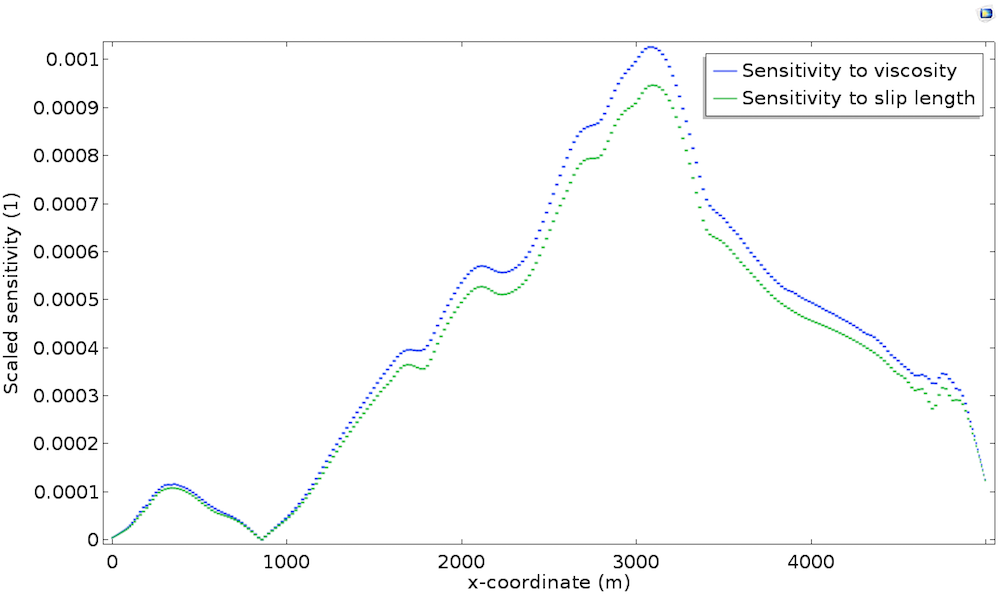
我们可以看到,两种灵敏度都与地形和厚度密切相关,但最重要的是,我们观察到两种灵敏度几乎相同。这是因为在基岩处,黏度\mu和滑移长度L_s扮演同样的角色。事实上,如前一篇文章所述Navier 滑移边界条件可以写作u_t=\frac{L_s}{\mu}\tau_{nt},因此滑动与成比例\mu/L_s。因此,就模型响应而言,黏度的扰动等同于滑移长度的扰动。
保留关于最高敏感度的两个要点,即:
- 出现在滑移长度和黏度上,并仅位于基岩上
- 与基岩的地形有很强的相关性(使它们既重要又难以观测)
由于黏度和滑移长度在基底滑动中起着相同的作用,很明显,数据同化工作必须集中在最不精确测量的量上,即滑移长度。虽然已经进行了严格的实验室工作来推导黏度的本构定律,而滑移长度的大多是不可测量的。
数据同化
让我们继续进行实际的参数识别测试。基于前面的结论,我们进行了两个实验来确定:
- 沿基岩的滑移长度
- 基岩的形状
对于滑移长度的识别,我们只需要用优化研究代替敏感性研究。节点其实没什么不同。在最优化节点有一个稍微方便一点的选项是定义成本函数:最小二乘目标节点,这样我们就不用定义插值函数和编写最小二乘成本函数了。相反,我们可以直接指向数据文件。

然后我们需要使用坐标列和值列子节点来指定它的结构。
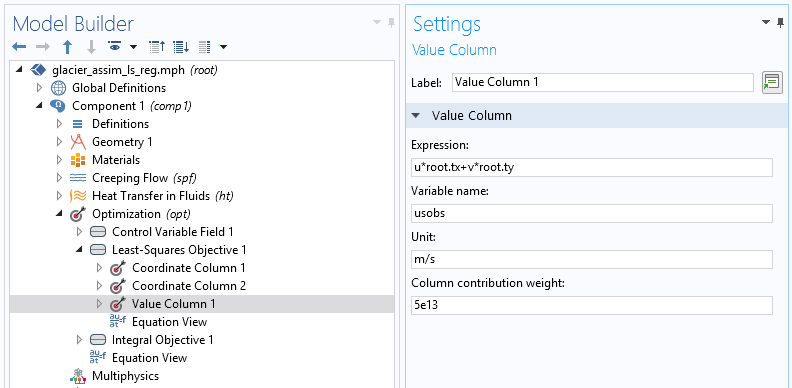
在双坐标列中,数据点第一列包含x-坐标,第二个包含y-坐标。值列用于根据模型变量查找数据文件提供的量(切向速度)。单位对于精度很重要(例如,在数据文件包含以米/年为单位的速度的情况下)。权重对于优化算法也很重要。由于最小二乘成本函数没有标准化,所以这个值对于衡量目标最小化是必不可少的。该功能完全依赖于模型,通常需要几次尝试才能正确调整。
默认值为1,成本函数的绝对值非常小(因为它是一个速度),优化算法会立即退出,并显示以下消息:
如果可能,为了帮助优化算法,我们可以基于物理考虑来定义控制变量的界限,以限制可接受的最小化空间。边界可以直接在最优化节点作为控制变量定义的子节点被定义。
我们还需要在研究中添加一个优化节点。我们不需要调整这个优化节点,因为信息是通过优化接口提供的。然而,优化算法的选择很重要。默认选项(Nelder-Mead)在这里不适合,因为它是一个限于标量值控制变量的无梯度求解器。我们将使用 SNOPT 求解器,这是一种非常有效和通用的基于梯度的算法。
研究在 50 次迭代及 1 分钟内收敛。我们绘制了推断的滑移长度值和原始(目标)值:
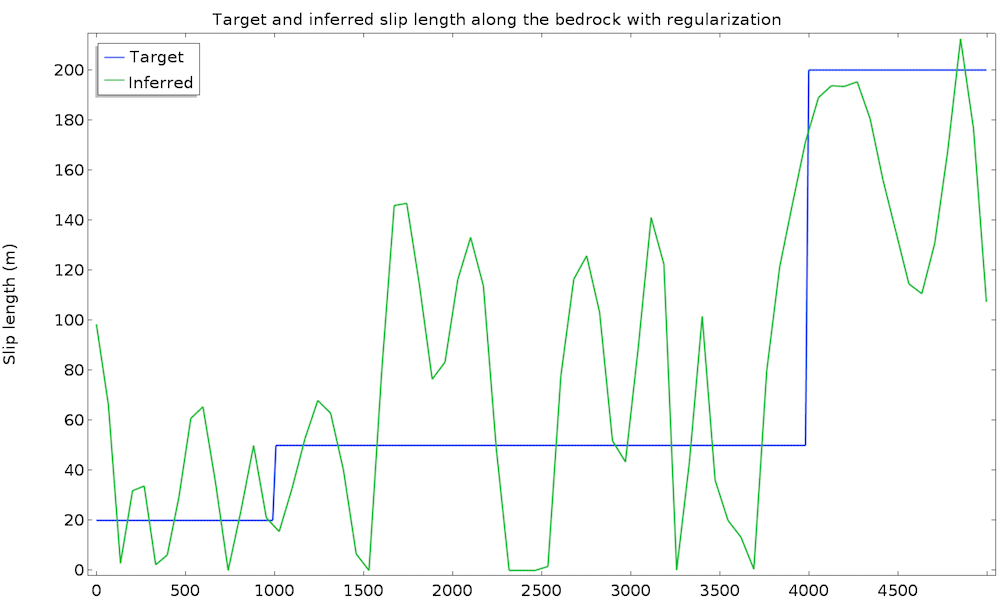
考虑到我们推断滑移长度值,这是一个很好的初始结果。然而,我们可以预期一个更接近真实滑移长度的值。为了提高识别值,我们可以引入一些关于滑移长度的额外信息。例如,我们可以假设滑移长度具有更高的规律性,因为这种快速变化的结果在物理上似乎并不合适。这个方法叫做正则化并且几乎总是在数据同化中用于过滤高频以便更接近检索的主要成分。正则化是通过在成本函数中简单地添加一个项来实现的,该项惩罚了控制变量的过大梯度,因此最小化成本函数将需要更规则的滑移长度。添加一个由\int_{\Gamma_s}|\nabla L_s|^2 dx定义的积分目标节点:
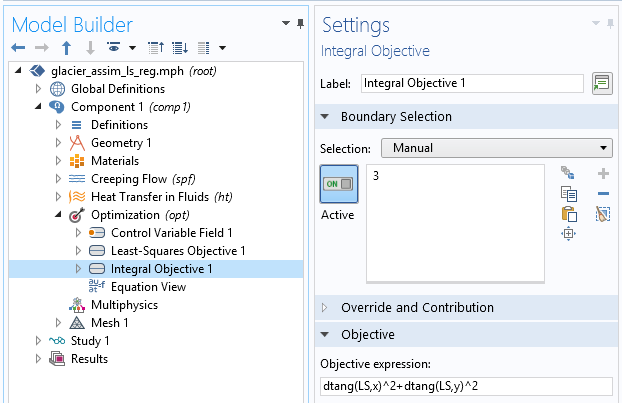
额外的正则项定义。
再次运行研究,并在 25 次迭代和 30 秒内收敛。成本函数现在由两个项组成,全局目标仅由两个目标的加权和来定义,结果如下:
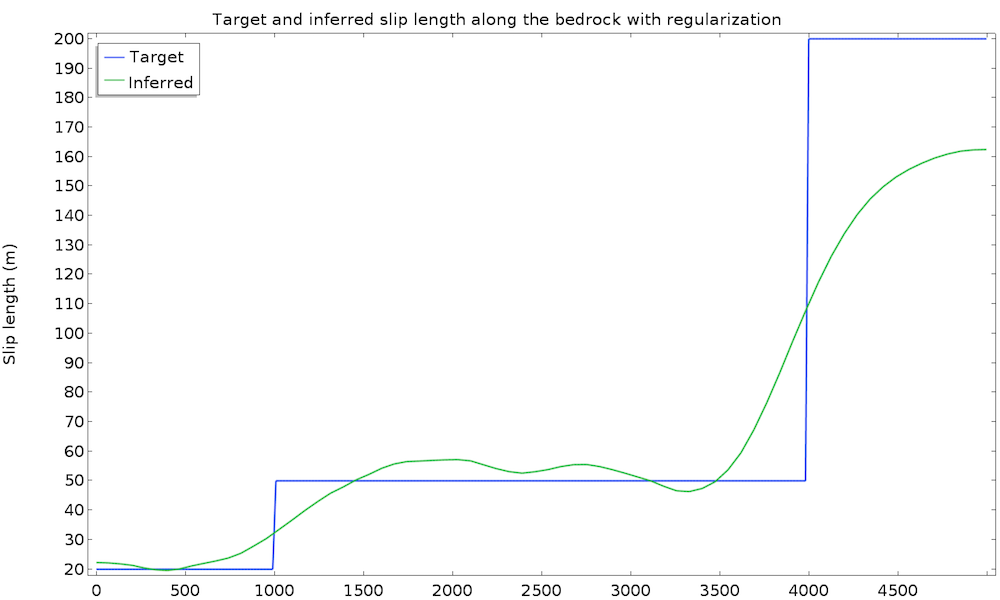
这一次识别出的滑移长度非常令人满意,非常接近真实值。请记住,我们仅使用了 50 个精度为 10% 的地表数据点,以及一个非牛顿、非等温流体流动模型。
请注意,正则化项没有添加权重,因为自然值恰好非常合适。然而,权重通常需要根据最小二乘项进行调整。太大的正则化会导致一个常数识别变量,而太小则是无效的。
现在,让我们推断地形本身的形状。这个例子稍微复杂一点,但是涉及的过程是一样的。我们想定义一个决定基岩形状的控制变量,所以我们需要找到一种使底部边界变形的方法。我们可以在边界上定义一个位移d_b(x)和一个同构的垂直拉伸因子,以使变形在边界处最大,并随厚度的增加而减小,直到在表面处达到零。已知y_b(x)为底边界的高度,y_s为曲面的高度,则该因子可以简单地由(y-y_s)/(y_b-y_s)给出,域的变形可以写作:
其中,d_c是在基岩上定义的控制变量。
这种变形是使用 ALE 移动网格功能引入的。成本函数保持不变,并且也介绍了d_c上的正则化。为了简化,我们在与之前相同的例子上运行识别,但是对于合成数据,假设基岩处的速度为零。这是因为当滑移长度较大时,地形的作用会大大减弱,从而更难准确识别。底部为无滑移条件,几何图形使值更容易检索。
结果显示了从初始几何到收敛的优化过程中区域形状的演变。在下面的动画中,绿色背景代表目标几何体,黑色网格是优化的网格。结果达到了非常好的精度。几何形状的两端都没有很好地调整,但这是自然的,因为速度为零,成本函数和梯度也为零。
结束语
逆向建模是一个非常强大的工具。它需要一些优化知识来定义相关的成本函数(也可能是正则化)和一些物理理念来区分控制变量。灵敏度分析是深入了解进入口参数上的扰动如何通过模型传播并影响解的良好起点。
一般来说,你应该一次推断尽可能少的参数(理想情况下是一个),因为一次识别几个参数通常会导致所谓的等效性:由不同的参数组合导致相似的解。 考虑到我们的数据精度有限,解可能无法区分,随着参数的增加,问题会越来越多。
下一步
联系我们,了解更多关于如何利用优化改善您的建模结果的信息。

评论 (0)