

二十年前,配备了多达 1000 个处理单元的向量处理器超级计算机在超级计算机 500 强中占据了统治地位。随着时间推移,大规模并行计算集群不仅迅速取代了向量超级计算机成为了榜单中的新霸主,同时还促使了分布式计算的兴起。集群的每个计算节点上最初只有一个专用于高性能计算的单核处理器,很快,人们针对需要共享内存的节点,增加节点上的处理器数量,并以这种具备内存共享能力的并行计算机为基础,开发出了多核处理器,满足了各类计算应用对高效算法的需求。再看今天的超级计算机 500 强排名,我们会发现当中大多数集群均由数量众多的计算节点组成,每个节点又包含多个插槽(socket),每个插槽连接着最多可达八核的多核处理器。并行计算是一种适用于共享内存计算系统的技术,与基于分布式内存的集群采用的并行计算技术全然不同。为了实现高效率的并行计算,我们需要一种两者并用(混合)的机制。
共享和分布式内存
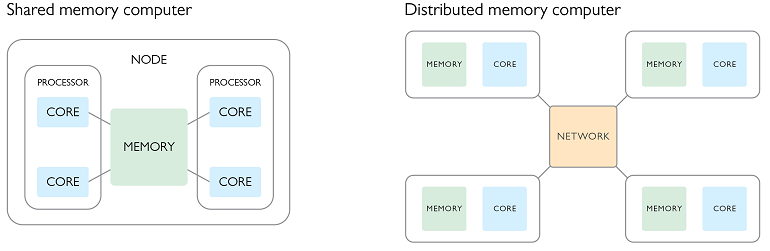
并行计算主要有两种经典的实现方式:共享内存和分布式内存。虽然二者的最终目的都是利用并行硬件提高运算效率、扩大计算规模,但是这两种机制在结构方面存在许多差异。(注:美国劳伦斯利弗莫尔国家实验室网站提供了详细介绍并行计算的学习资料。)
这两种方法的名称本身便表明了二者的基本差异。在共享内存计算系统中,整个程序的各个分布进程并行运行,共享相同的内存空间。这种方式保证了数据在核心和处理器之间高速传输,但主要缺点是共享内存节点上的计算资源有限。如果问题规模扩大,或者需要引入更多核心来减轻每个核心的计算量,人们却不能增加更多资源。综上所述,共享内存计算的扩展性较差。
在分布式内存计算系统中,内存是由多个并行进程分配的,而非共享的。这些进程必须通过发“消息”进行显式通信,所以通信和同步会耗费额外的时间。我们应该利用数据局部性,并改善算法,尽可能地减少通信量。分布式内存计算的一大优势是出色的扩展性,轻松支持增加更多可用的资源(节点,核心与内存资源)。
根据经验,我们可以总结出一个简单的原则:对于核心数量极多的计算机,应使用共享内存;对于由多个计算节点组成的集群,则应使用分布式内存。
混合并行计算
从处理器市场的发展历程中,我们可以发现一个明显的趋势:处理器不再通过提高时钟频率,而是通过不断增加核数来增强性能。AMD 公司于 2004 年发布了世界上第一款 x86 双核处理器。到了 2013 年下半年,英特尔发布的一款处理器已经升级到了 12 核。如果传言属实,英特尔的 Knights Landing 技术可能会达到72 核!
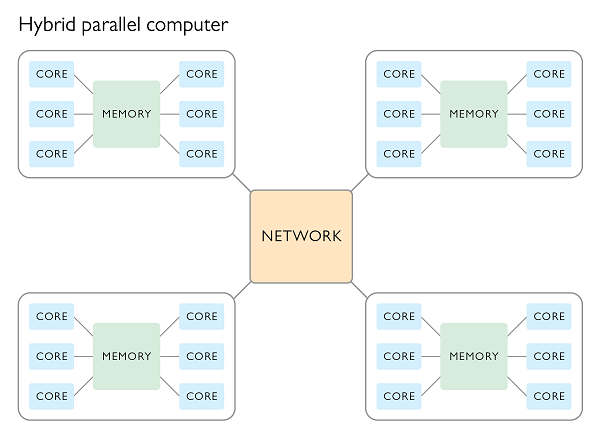
这也意味着,由单核计算节点组成的集群已经成为了上个世纪的古董。在世界超级计算机 500 强中,大多数集群计算节点上的每个插槽均安装了八核处理器。小型和中型计算集群也采用了相似的装置。这种配置的广泛应用使得混合运用两种机制成为必然:共享内存应用于节点内计算,同时分布式内存应用于节点间计算。这种做法的目标是最大限度地提升扩展性,并减少消息传输的成本,同时充分发挥共享内存的优势。混合并行计算结合了共享内存机制和分布式内存机制,提供了一种灵活适应所有计算平台的通用方法。如果正确地结合两种并行技术,就可以加快计算速度,提高扩展性,并且高效地利用硬件。
COMSOL软件与混合并行
默认情况下,当在一个多核并行工作站或个人计算机上启动 COMSOL® 软件时,软件会通过共享内存机制调用系统中所有可用的核心进行并行计算。在工作站或集群上工作时,用户可以控制所用的并行计算方法,选择分布式内存、共享内存,或者混合模式来运行仿真。您可以在《COMSOL 参考手册》中阅读相关操作的详细说明。
COMSOL Multiphysics® 及其附加产品专为计算耦合物理场问题量身定制。不同问题对应不同的最优并行配置,这主要取决于问题涉及的底层物理场、模型的耦合程度、问题规模和求解器选择。COMSOL 软件内置了精细的选项控制,供您挑选与具体问题对应的最佳并行配置。

评论 (0)