
高性能计算(HPC)
高性能计算
高性能计算简称HPC,是指利用聚集起来的计算能力来处理标准工作站无法完成的数据密集型计算任务,包括仿真、建模和渲染等。我们在处理各种计算问题时常常遇到这样的情况:由于需要大量的运算,一台通用的计算机无法在合理的时间内完成工作,或者由于所需的数据量过大而可用的资源有限,导致根本无法执行计算。HPC 方法通过使用专门或高端的硬件,或是将多个单元的计算能力进行整合,能够有效地克服这些限制。将数据和运算相应地分布到多个单元中,这就需要引入并行概念。
就硬件配置而言,常用的类型有两种:
- 共享内存计算机
- 分布式内存集群
在共享内存计算机上,所有处理单元都可以访问随机存取存储器(RAM);而在分布式内存集群中,不同的处理单元或节点之间无法访问内存。在使用分布式内存配置时,由于不同的处理单元不能访问同一个内存空间,因此必须存在一个相互连接的网络,才能在这些单元之间发送消息(或者使用其他通信机制)。鉴于有些单元共享共同的内存空间,而其他单元又是另一种情况,现代 HPC 系统通常是融合了这两个概念的混合体。
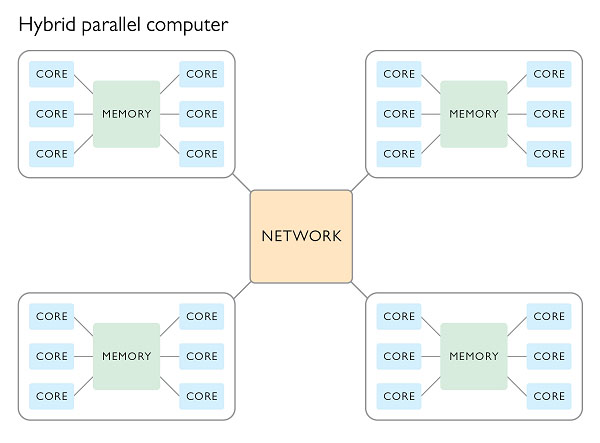
- 混合并行计算(HPC 的重要组成部分)的动态示意图。
为什么要使用 HPC
使用 HPC 的原因主要体现在两个方面。首先,随着中央处理单元(CPU)和节点数量的不断增加,人们可以使用的计算能力越来越多。有了强大的计算能力,就能在单位时间内执行更多运算,从而提高特定模型的计算速度。这就是我们所说的加速比。
加速比通常定义为:同一个任务在并行系统的执行时间与在串行系统的执行时间的比值。
加速比的上限取决于模型并行求解的程度。举个例子,假设一个运算量固定的计算任务,其中 50% 的代码可以并行执行。在这种情况下,理论最大加速比为 2。如果并行执行的代码能够上升至 95%,则理论最大加速比很可能达到 20。对于能够实现完全并行的代码,可以不断向系统中添加计算单元,因此不存在理论上的最大限制。阿姆达尔定律对这一现象进行了解释。
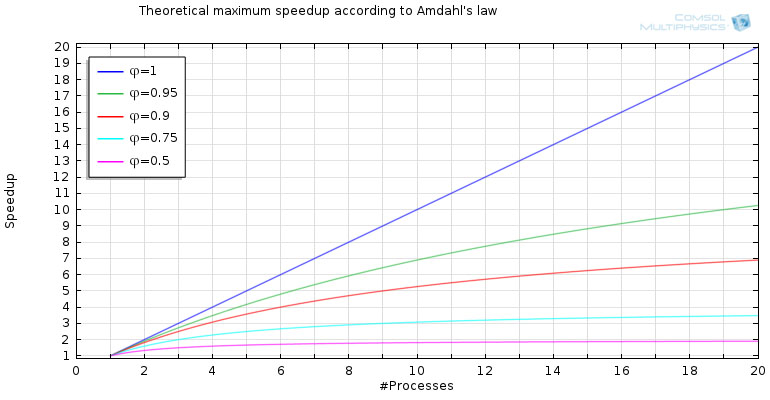
- 绘图根据阿姆达尔定律描绘了理论最大加速比。
另一方面,在集群的情况下,可用的内存量通常以线性方式增加,同时包含更多的节点。如此一来,随着计算单元数量的增加,就能够处理越来越大的模型。这称为扩展加速比。从某种意义上来说,运用这种方法可以对阿姆达尔定律提出的限制加以“欺骗”——该定律适用于固定大小的计算问题。将计算能力和内存提高一倍,就可以在相同的时间内完成大小为基本任务两倍的计算任务。Gustafson-Barsis 定律对这一现象作出了解释。
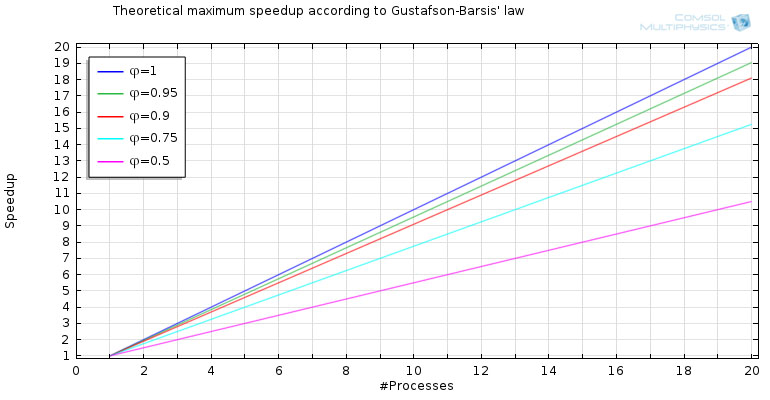
- 绘图根据 Gustafson-Barsis 定律描绘了理论最大加速比。
并行化
不同类型的建模问题具有不同的可并行程度。以参数化扫描为例,这种问题求解多个具有独立的几何、边界条件或材料属性的相似的模型,几乎可以完全并行计算。具体的实现方法是为将每一个模型设置分配给一个计算单元。这类问题非常适合并行计算,因此通常称为“易并行问题”(embarrassingly parallel problem)。
易并行问题对集群中的网络速度和延迟非常敏感。(在其他情况下,由于网络速度不够快,无法有效处理通信,很可能导致速度减慢。)因此,可以将通用硬件连接起来,加快这类问题的计算速度(例如,构建Beowulf 集群)。

- Beowulf 集群。
有些问题可以分解为多个更小的部分,或者说是子问题。例如,可以通过数据分解(数据并行)或任务分解(任务并行)来进一步分解问题,通常这些子问题之间的耦合程度会直接影响它们的并行化程度。
举例来说,易并行问题便是一个几乎可以完全解耦的问题,如前面讨论的参数化扫描。而完全耦合问题的例子则是一个迭代过程,其中
的计算必须以严格的串行方式进行。
当多个子问题相互耦合时,由于一个子问题的中间结果可能依赖于其他子问题,因此不能单独进行处理。我们需要通过信息交换(与原始串行问题相比,还包含一些其他工作)来处理这些依赖关系。共享内存或互连网络可用于在不同的计算单元之间进行通信和同步。根据计算任务是在共享内存环境下还是在分布式内存环境下运行,有众多因素会对可并行化以及潜在加速比产生影响。
在多个节点上运行分布式内存仿真时,各个计算单元必须使用网络进行通信。此时,网络延迟和带宽会进一步影响通信速度。正因如此,大多数 HPC 集群都配备了高带宽/低延迟网络,实现在集群的各个节点之间快速传输数据。
发布日期:2016 年 3 月 7 日上次修改日期:2017 年 2 月 21 日